Introduction
Each summer, HRT’s Software Engineering interns work with mentors, teams, and longtime HRTers on independent programming projects that tackle the most interesting problems in the world of automated trading, making a notable impact on our day-to-day operations.
This particular intern spotlight series highlights the work of four of our 2024 Software Engineering interns, all of whom will be joining us full time in the not-too-distant future:
- Parrot Pneumatic Tubing by Alex Yi
- Building a High Performance NIC-to-NVME Data Service by Alex Burton
- Signal Stream Compression by Charlotte Wang
- Non-COD OpenOrderServer by Liam Patterson
Parrot Pneumatic Tubing
by Alex Yi
It’s like a drive-through bank.
Background
At HRT we have a ton of internal trading APIs written in C++ which give us precise and efficient control over our systems. However, at times there is a desire to write succinct high-level code to express a new trade. For that, we have a system called Parrot (née ToucanServer).
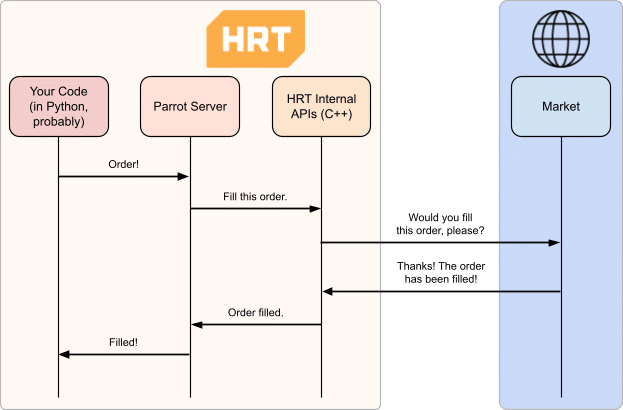
The client-server design’s flexible, so we’re not tied to one client implementation, but client-server chatter uses gRPC under the hood, which incurs the overhead of a HTTP call per request (per order sent). When you also consider the extra network hop and the blocking behavior of the gRPC client, sending orders in a loop becomes unacceptably slow.
What To Do?
gRPC is implemented over HTTP/2, which is great for scalability but not bandwidth: each (possibly small) individual order pays the cost of HTTP headers, burning through bandwidth.
Instead we can send the headers just once! gRPC has a streaming protocol, allowing us to open just one long-lived request, which can then be used to pass multiple messages. Patching Parrot to do this was my project!
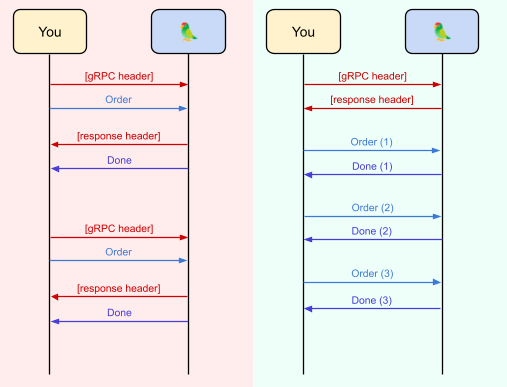
To send a request with this new API, you wrap it into a stream-ready request and push it into the long-lived stream. The server will then unwrap it and dispatch it to the appropriate response handler and finally send a response back the way it came. Instead of trudging to the counter, waiting for the teller, and then trudging back, you get that glorious “FOOMP” as your check zooms away in a pneumatic tube. Ergonomics!
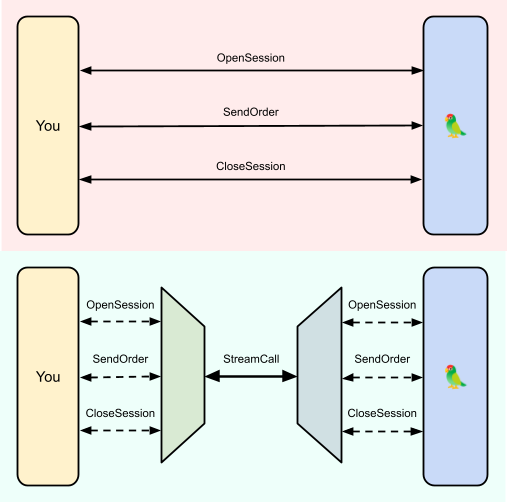
To facilitate this, each stream call comes with a “clientUID” – a unique identifier that allows outgoing responses to be matched with incoming requests. Ultimately the server-side retooling was pretty minimal and mostly consisted of keeping track of clientUIDs and changing each handler to treat stream and normal calls equivalently.
Unfortunately things were messier on the client side! Something has to handle the long-lived stream and responses might arrive out-of-order. So, I reimplemented the core of the client to use asynchronous operations under Trio to handle all the concurrency, while keeping the same API but using async functions instead. This also allows for sending multiple orders at once (with something like asyncio.gather) should the need arise!
Impact
The ability to send many concurrent orders without having to muck around with threads is fantastic. But most importantly it all has been done unobtrusively, so Parrot devs can add more features with minimal hassle, and clients can reap the benefits just by sprinkling “awaits” into their existing code. Win-win!
Building a High Performance NIC-to-NVME Data Service
by Alex Burton
HRT’s research environment has ever-increasing demands for high-throughput, low-latency distributed data storage. We have been prototyping several new storage systems, one of which is a design inspired by the Pangu [1] filesystem.

Distributed file systems involve many different parts. In order to find something interesting for roughly 10 weeks of work, we focused on the data path between a client and a data server.
The Data Path
A data server provides a simple API over the network: a key-value store where entries can be created and deleted, and where values can be read from or appended to. Our first task was implementing this API locally.

Figure 2: Magnified view of the data path. The data server (1) implements the key-value API locally, and (2) exposes the API over the network.
Local Key-Value Storage
As our baseline, we used a simple implementation on top of ext4 files using the trusty posix API to pack key/value tuples into files. Even when using multiple cores, this approach only yielded 1700 MB/s of multithreaded append throughput on an NVMe drive capable of 3800 MB/s write throughput.
To obtain better performance, we decided to remove as many layers of abstraction as we could and interface directly with the NVMe device. To do this, we used Intel’s Storage Plane Development Kit (SPDK) [3] . We divided the drive into fixed-size write units. If the write unit size is large enough–around 128 KB on our test drive–we can hit the max raw write throughput of the drive with a single core by issuing random writes of this size, one after another. To avoid the overhead of journaling, we include a header in each write unit to allow each write to be self-identifying. To support fast reads, we store an in-memory map containing metadata for every key. If the server crashes, we can rebuild this map by scanning the disk and looking at the headers of each write unit. In the future, we would divide the drive into extents (fixed-size non-overlapping regions), checkpoint metadata, and limit recovery scanning to only extents that weren’t covered by the checkpoint.
Key-Value Storage Over the Network
At this point, our performance with a local workload was nearly matching the raw disk throughput, reaching 3600 MB/s of appends to random keys. To allow for workloads over the network, a simple solution would be to spin up an RPC server on top of the Linux TCP stack. However, Linux has relatively poor throughput and tail latency for networking, as suggested in the Luna paper [4]. The major culprits are unnecessary copies and scheduling overhead [2, 4]. To bypass these, we used the Data Plane Development Kit (DPDK) [5] to directly interact with the NIC, allowing us to write zero-copy run-to-completion packet processing code.
From here, we designed and implemented a simple RPC protocol (over UDP) on top of the key-value API. Since the maximum ethernet packet size is relatively small, each append RPC call needs to be split into multiple packets. Fortunately, NVMe drives support (restricted) scatter-gather lists for host memory buffers, so we can still perform zero-copy NVMe writes when the data to be written is scattered across many packets.
Finally, after implementing the RPC protocol, we wrote a client load simulator. From benchmarking, we observed that the server was easily able to handle the incoming packets and issue appends at the speed the client could send them (around 2.6 GB/s–approaching the ethernet link capacity). Thus, we concluded interacting with the hardware directly in user-space unlocks much greater throughput with lower CPU usage.
Bibliography:
1. https://www.usenix.org/system/files/fast23-li-qiang_more.pdf
2. https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44271.pdf
3. https://spdk.io/
4. https://www.usenix.org/system/files/atc23-zhu-lingjun.pdf
5. https://www.dpdk.org/
Notes:
https://www.hudsonrivertrading.com/hrtbeat/intern-spotlight-2023-software-engineering/
Signal Stream Compression
by Charlotte Wang
Market data enters our trading system as a stream of irregularly timed events corresponding to changes in the financial market: an order is placed, a trade is reported, a quote is published. In general, it’s useful to have such data re-sampled to be reported at regular intervals. We could then answer questions like: what was the mid price of AAPL at 10:00? In this system we refer to this re-sampled data as a “signal”, which is then transmitted to live-trading machines or saved to disk for future analysis. The efficient streaming of signals across networks and disks is thus an important problem at HRT. The focus of my project is to improve the compression of these signal streams.
Data Characteristics
At each regular point in time, we need to transmit a row of sometimes dozens, sometimes thousands of signals. Because each signal is a time-series formed from irregularly-timed events, each metric changes very little, if at all, from one point in time (timestamp) to the next. This allows us to perform high levels of compression.
Previously, rows were compressed by streaming the difference from the preceding row’s values. However, this only compresses identical values, and does not compress any values that have changed from row to row, even values with miniscule differences. Another inefficiency is that each entry includes an index of the changed value, meaning that the size of entry is dependent on the number of signals being transmitted per row.
The Solution
In order to compress values with minuscule differences, we perform “XOR Compression” on these values, which are represented as a series of doubles.

These bits are roughly transformed into a real number via the formula:
(-1)sign* fraction*2exponent. Combined with the relatively stable magnitudes and precision of the time-series, we have that for a signal:
- The sign and exponent bits for should be unchanged through time
- Most data does not use the full fraction for precision, leaving the latter bits zero and unchanged through time.
Thus, the XOR between signals for adjacent times has lots of leading and trailing zeros that we can leave out (see scheme below).

This XOR compression scheme eliminates the need for indices of changed values. By consolidating multiple logical values into contiguous bytes, a single ‘0’ bit can encode “no change,” allowing us to simply record the updates for each value.
Results


As expected, many of the compressed values need only 1 bit because there is no change. Most values are compressed to 20 – 50 bits, grouped by different precision classes. I tested this new compression strategy on a selection of 5 different sample data workloads. Each 64-bit double was compressed to an average of ~10 bits, half of the ~20 bits required from the previous signal diff format!
Open Order Server for non-Cancel-on-Disconnect orders
by Liam Patterson
At HRT we generally want our open orders to be canceled if we lose connection to the market in order to reduce risk. As a result orders are typically configured to be cancel-on-disconnect (COD). However, as HRT expands into new markets and styles of trading, there’s an increasing need for orders that don’t have this behavior. Canceling auction orders, for example, is considered risk-increasing since we expect those orders to be filled.
Problem
In order to understand our exposure on the market, we need to know our currently open orders. There’s limited infrastructure in place to monitor open non cancel-on-disconnect orders. The source of truth for open orders is our order entry server, called Trip, which is the process that connects to exchanges and sends orders. As we trade Trip multicasts events and writes these events to a log file. We have two existing options for discovering our open orders. The first is to read the massive log output sequentially, which is a slow process. The second is to directly ask Trip for its open orders, but this interrupts regular trading, and more importantly doesn’t work if Trip crashes.
Solution
For this internship, I developed the Open Order Server (OOS): a process which subscribes to Trip multicast data and keeps track of non-COD open order state. When a process wants to query its open non-COD orders, it asks the OOS rather than the Trip. The server maintains the set of open orders for trips that go offline (either intentionally or due to a crash).
During normal operation, the OOS tracks order state by listening to streamed multicast data. On startup the OOS first needs to initialize its state from Trip if the latter is already running. It does this by requesting open orders from Trip, which is similar to the existing workflow. However, if OOS starts while Trip is down, then the server reads the log file instead. As soon as a trip comes online, the server will try to connect to it and request open orders directly.
OOS Trip State Diagram:

One technical challenge was to implement the smooth transition between the refresh and the live streaming data without any gaps. This transition was mostly handled by an earlier intern project, but I had to extend the existing logic to support refreshing all open orders as opposed to being limited to orders for a predetermined set of symbols.
By the end of my internship the OOS was able to refresh state from trip order logs, listen to multicast order data, and respond to queries about open orders. Now we are able to quickly and reliably know our market exposure whether or not Trip is running, which enables HRT to explore new trading around non-COD orders.