Algorithms play a central role in algorithmic trading – as you might guess from its name. The simplest mental model of an algorithm is one of a black box that takes in data as input and outputs trading decisions. As researchers, we spend a lot of time thinking about what happens inside of that box. That translates into lots of diversity in the internals of trading strategies.
However, there is one thing that all algorithms have in common: if the data they ingest is fundamentally flawed, they are destined to fail. “Garbage in, garbage out” sums it up. In this post, I share the broad strokes of how we think about data quality and provenance in order to give our trading strategies a fighting chance to succeed.
What do we want from data?
There is an objective yardstick with which to measure any dataset: the improved performance of optimal trading strategies when they get to condition on the dataset vs when they don’t. Unfortunately, applying the yardstick is expensive. It takes time and effort to build trading strategies, much less find one that’s good enough to earn the term “optimal.” We’d like to know which datasets are valuable so that we can focus on those and not waste our time on useless ones. To that end, we apply heuristics to make initial judgements about how datasets will fare when scrutinized further.
Relevance
Let’s start with the most prominent heuristic: is there a reason to believe the data could be predictive of future asset prices? What makes it relevant? There are lots of datasets we can confidently dismiss in this spirit: sunspot events, UFO sightings, etc. In fact, if we didn’t dismiss them off-hand, our real discoveries might get lost in a sea of spurious correlations.
These fanciful examples are clear-cut, but most datasets we’re considering aren’t quite as obvious. For example, say you’re presented with a dataset of all Reddit posts and comments. Should that dataset be relevant to pricing US stocks? Maybe? Good researchers develop simplified mental models of how the world works that help them answer questions like this one. The best researchers (in addition to being technically strong), constantly refine their mental models as they make sense of disparate observations.
Uniqueness
Our job at HRT is to model asset prices and help the market reflect the “right” prices. To that end, we compete with other trading firms and sophisticated investors who have the same goal. If a dataset is already being widely used by our competitors, we can’t expect to add much value by using the same data in the same way. What does this mean for evaluating datasets? Simple datasets that are widely used—even if indisputably relevant—might not fare very well.
For example, the Price-to-Earnings (P/E) Ratio is a widely reported metric about companies. If I Google “AAPL stock,” Google displays Apple’s P/E ratio above the fold. The P/E ratio is the quotient of the share price and the earnings per share, and roughly speaking, it captures how “expensive” the company is. It’s incredibly relevant to investors. Yet, if you wanted to make a trading strategy solely using P/E ratios, you might be underwhelmed by its performance given the importance of the metric. We could say it’s already been “priced in,” which is to say that this is information so many people have extracted that it doesn’t provide our strategies a competitive advantage.
The most exciting datasets are novel or complex enough that we can hope to extract something from them that our competitors do not.
Avoiding lookahead
Let’s think through a hypothetical. Say you’re approached by a newspaper which has a new data product targeted for investors: Market Moving News Articles™ (MMNA). The newspaper has recently identified that most of its articles don’t matter to investors, and it wants to add value by delivering *tagged* articles. In addition to the regular article contents such as the text context, time of publication, author’s name, headline, etc. , whenever a new article is published, subscribers of MMNA will get three extra fields annotated by the newspaper’s stock analyst: affected_stock_ticker, is_market_moving, and is_good_news. They graciously offer you a trial of five years of historical data. You backtest a simple strategy of buying (selling) the stocks with good (bad) market moving articles and it looks great. What’s wrong with this picture?
How did they get the tagging of five years worth of articles if they just recently had the idea to tag articles? If they had the foresight five years ago to start tagging articles real-time then there’s nothing wrong. But let’s say they didn’t. Instead, they had their analyst look through past articles and retroactively tag them. This, though unintentionally so, is incredibly dangerous! There are all sorts of ways in which the analyst might be benefitting from hindsight to make better annotations than would have been made in the moment. The MMNA historical dataset is rendered effectively unusable.
Lookahead can manifest in subtle ways. It’s imperative as researchers to stay vigilant and understand the provenance of the data we work with to dodge these traps.
Sample size and noise
Otherwise useful data could be disqualified if there is too little of it or if it’s too noisy. Thanks to simplifying assumptions and statistics, we can usually get a reasonable idea of whether this will afflict us even without looking at the dataset.
The US Bureau of Labor Statistics (BLS) publishes monthly statistics on employment (such as the unemployment rate) that are closely watched. Say a hypothetical survey company constructs a high-fidelity random sample one day before the BLS to try to independently estimate the unemployment rate. However, constructing true random samples is expensive, so they only survey 250 people (and report the proportion who are unemployed). They are offering to sell you the survey result for $X, but won’t show you their data before you pay them. Are you interested? (Assume you believe their methodology is airtight.)
Our best tool to answer this sort of question is some back-of-the-envelope statistics. How much uncertainty is there in the new unemployment rate the BLS will announce? We can upper bound this by fitting a simple auto-regressive model to the unemployment rate. Let’s say our model has prediction errors with 0.5 percentage points of standard deviation. What is the standard error of the proportion in the survey? Modeling as a binomial distribution and assuming unemployment is around 5% yields
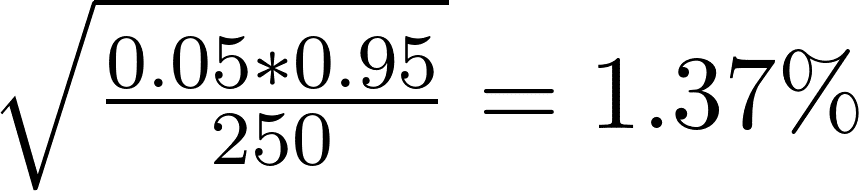
If we assume the survey is an unbiased estimator for the BLS figure and it’s uncorrelated to our autoregressive model’s errors, that means we’d be able to improve our autoregressive model error standard deviation to
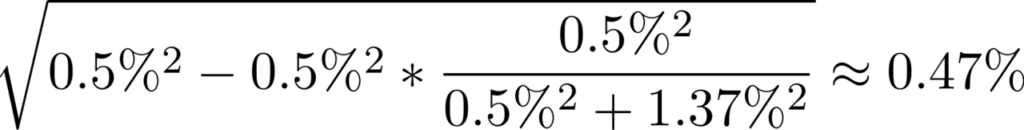
We could then use some further back-of-the-envelope math to conclude whether our trading strategy will benefit from an additional 0.03% in predictiveness on the unemployment rate more than the cost of the data (we’d need some model of the sensitivity of asset prices to the unemployment rate).
Where do we get data from?
We’ve talked about how to evaluate the potential of certain datasets, but where do we actually get data from?
Market data
Financial markets generate a prodigious amount of data, primarily in the form of orders and trades made on exchanges. The data is unquestionably relevant and complex; in other words, it checks off all the boxes for data we could expect to be useful.
Let’s consider one possible use of market data. Companies do not exist in a vacuum – they are all interconnected in various ways. A chip-maker sells to a phone-maker; an app-maker sells on the phone’s platform; an advertiser buys ads on the app; the list of relationships goes on. Stock prices have to somehow reflect these relationships. A simple model for these relationships is that similar stocks should have similar stock returns. Thus, you could conceivably use the data of AAPL stock returns to predict, say, MSFT stock returns. And of course, things can get arbitrarily more complex than this basic “pairs trade.”
Alternative data
Widespread computer usage has made it easier to collect granular data about all sorts of things that aren’t securities but could be related. This type of data is the hardest to describe because the datasets are proprietary and no two datasets are exactly alike. For example you could purchase data on foot traffic to various stores, capture twitter streams, or even track wind patterns in various geographies.
It is worth noting a recurrent commonality in this type of data: the relationships can be delightfully creative and/or surprising! To provide an example I’ve not personally verified but which sounds plausible: there is evidence to suggest that angry reviews claiming Yankee Candles are scentless coincide with surges in COVID-19 prevalence.
Data Transformations
This may seem like cheating, but data transformations can sometimes so fundamentally change a dataset that in effect you’ve made a new dataset.
Say you start with a dataset of all trades in US stocks. As is, this data is already plenty interesting. However, let’s consider a character-changing data transformation on it. Roughly speaking, US Regulation (SEC Rule 612) prohibits exchanges from quoting prices in discretizations smaller than one cent while allowing sub-penny price improvement (subject to some limitations). This sub-penny price improvement is particularly characteristic of wholesalers who provide these small “discounts” to retail customers. Thus, if you transform the data into the proportion of trades with sub-penny prices, you’ve made a proxy of retail interest across stocks and across time.
There are all sorts of research questions you can ask of a dataset of retail participation that you couldn’t directly ask of a dataset of trades. New data!
Parting thoughts
This was just a short, high-level overview of how we think about data at HRT and its profound impact on the quality of our strategies. Notably, there are many important things not covered here. For example, good engineering practices are critical to both research with and productionizing data, particularly when the datasets get large. There are also many nuances particular to the different types of data (whether time-series, textual data, etc.). If these types of problems sound interesting to you, take a look at our current openings!