Introduction
Having an accurate high-level overview of market dynamics is crucial in algorithmic trading. At HRT, many trading teams curate their own models to understand risk and performance profiles of their portfolios. Here we’ll dig into a specific class of models called factor models and understand how it encapsulates asset relationships, allows for portfolio optimization, and explains investment performance attribution.
Modeling
The first step to making money and managing risk in the stock market is having an accurate model of where the sources of profit and loss are coming from. We’ll go through some basic modeling assumptions and introduce some ways a portfolio manager might evaluate their positions in the market. For simplicity, say that you observe prices $p_t$ of an asset (say, AAPL) at the end of day $t$. The close-to-close returns are defined as:
$$
r_t = \frac{p_t}{p_{t-1}} -1
$$
We have such returns for every asset, every day. Wouldn’t it be nice if these returns could be described by a simple model? We are not aiming for the fanciest model of all (say, the turbo–encabulator of returns models), but for something simpler and more reliable, yet not totally uncool and trivial. Here we’ll dive into a type of battle-tested models in this category called factor models.
Modeling Returns
Factor models are linear models that describe the return of a set of assets based on:
$$
\mathbf r_t = \mathbf B_t\mathbf f_t + \mathbf \epsilon_t
$$
This resembles a good old linear regression, but with different symbols:
- $\mathbf r_t \in \mathbb{R}^n$ denotes the assets’ returns;
- $\mathbf B_t \in \mathbb{R}^{n \times m}$ is the loadings matrix;
- $\mathbf f_t \in \mathbb{R}^m$ is the vector of factor returns;
- $\mathbf\epsilon_t \in \mathbb{R}^n$ is the vector of residual (or idiosyncratic) returns.
In practice, for many asset classes the number of assets $n$ is much larger than the number of factors $m$. The loading matrix contains the essential information linking factor returns to asset returns. What is different from a traditional regression is that this is a dynamic relationship. The factor returns $\mathbf f_t$ are random variables, drawn in every period from a multivariate distribution which is assumed to be independent from the previous and next ones. Similarly, the “noise” $\mathbf \epsilon_t$ is random and independent from the factor returns. Here, “idiosyncratic” simply means “asset returns not explained by the loadings and returns.” Each return $\epsilon_{t, i}$ is independent of $\epsilon_{s, j}$ over time (when $s\ne t$) and across assets (when $i\ne j$). We can interpret this as a graphical model from underlying factors linearly impacting each asset’s return with some weight. To simplify notation a bit, let’s assume we’ve fixed $t=T$ and remove the subscript.
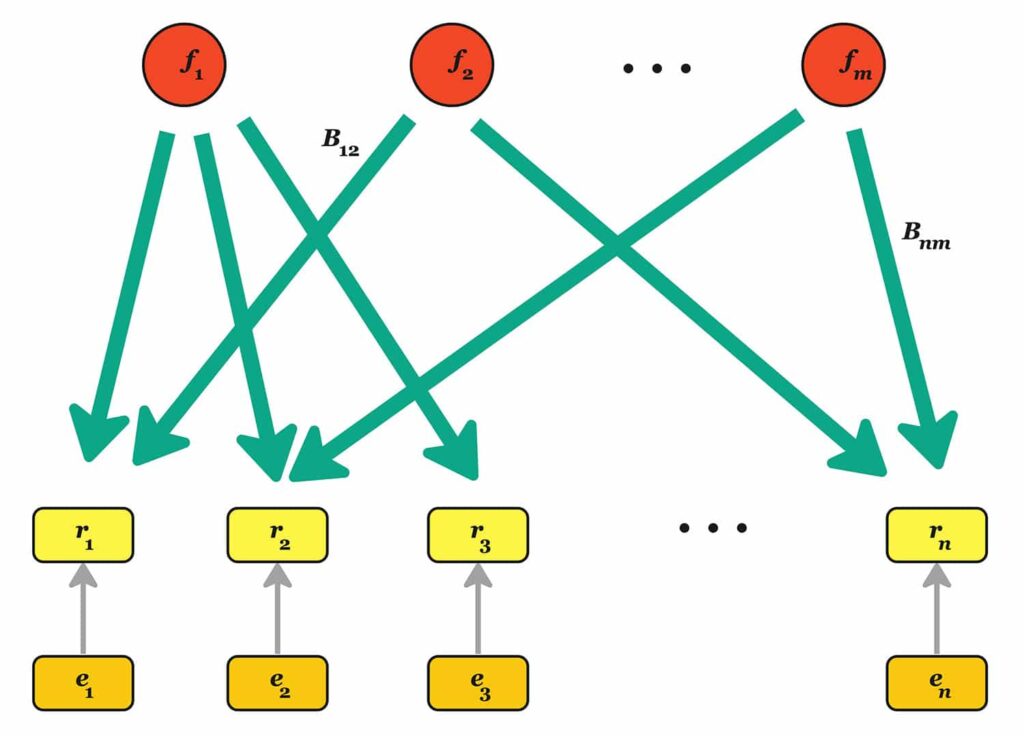
What is the interpretation of $\mathbf B$? Each column is an asset “characteristic.” For example, $b_{i,1}$ could take the value 1 if the stock $i$ is a tech company, and 0 otherwise. The daily returns of tech companies are positively correlated: GOOG, MSFT and AAPL move together quite a bit. A way to interpret this is to say that the first factor (the “tech sector” factor) is moving up or down, and that tech companies are partially driven by this factor. There are additional factors that can play a role. For example, some companies are more profitable than others, and “profitability” can be another factor. And last, there is the “noise” $\epsilon_i$: something that is very specific to a company, like the returns experienced on the day of an earning announcement. When journalists say “in a crisis all correlations go to 1,” what they really mean is “in a crisis some factors move a lot more than asset-specific returns, and as a result asset returns become more correlated.”
This relationship between asset returns and factors may seem intuitive, but it encodes so much subtle information about the market. Let’s see some questions we can answer with this simple but powerful tool!
Covariance matrix estimation
Having the covariance matrix of all the assets we can trade is useful. Why? Because it allows us to estimate the volatility of any portfolio. “Volatility” is a finance term to denote “standard deviation of something, at some time horizon.” In our case, imagine that we have invested $w_1=$ $-30M in TSLA, $w_2=$ $10M in AAPL and so on. The vector of our net dollar holdings is $\mathbf w$ and the returns covariance matrix of these assets is $\mathbf\Sigma_r$. The volatility of our portfolio is $\sqrt{\mathbf w’\mathbf\Sigma_r \mathbf w}$. This is the standard deviation of our portfolio’s daily dollar PnL. For many reasons we want to have a first estimate of the uncertainty at short horizon: we need to be adequately funded, and we need to set expectations for our swings. There is a problem: $\mathbf\Sigma_r$ can be really big. Between the Americas, Europe, and Asia, there are easily 10,000 liquid, tradeable assets – that’s 50 million values to estimate. The calculation also requires $n^2$ operations, which is demanding, especially if you have to run this many times per day, or even many times per hour.
Factor models to the rescue! If we know the distribution of the factor returns, we could estimate the uncentered empirical covariance matrix of the factors: $\mathbf \Sigma_{\mathbf f}=T^{-1} \sum_{t=1}^T \mathbf f_{t}\mathbf f_t’$. This is a fancy way of estimating variances and covariances of factors, assuming that the factor return means are so small that they do not make a difference in the computation. If we know the idiosyncratic returns, the calculation is even easier. Since these returns are pairwise uncorrelated, the covariance matrix is diagonal with terms $[\mathbf\Sigma_{\epsilon}]_{i,i} = \frac{1}{T} \sum_{t=1}^T\epsilon^2_{t,i}$. Now, we have the covariance matrix of our assets. With a bit of algebra, we get:
$$
\mathbf\Sigma_r = \text{Var}(\mathbf r) = \text{Var}(\mathbf B\mathbf f + \mathbf\epsilon) = \text{Var}(\mathbf B\mathbf f) + \text{Var}(\mathbf\epsilon) \mathbf =\mathbf B\mathbf\Sigma_{\mathbf f}\mathbf B’ + \mathbf\Sigma_{\mathbf\epsilon}
$$
Storing this matrix takes essentially $mn$ numbers, rather than $n^2$. Since there are typically less than a hundred factors, $m \ll n$, that saves us 2 to 4 orders of magnitude in space! Computing the volatility of our portfolio is also much faster. Since we want to compute $\sqrt{\mathbf w’\mathbf \Sigma_r \mathbf w}$, we could first compute the vector $\mathbf b:=\mathbf B’\mathbf w$, which takes $\sim mn$ operations. The rest is very fast, since computing $\mathbf b’\mathbf\Sigma_{\mathbf f}\mathbf b+ \mathbf w’\mathbf\Sigma_{\mathbf \epsilon}\mathbf w$ takes only $\sim m^2+n$ operations. Most importantly, covariance matrices from factor models often give more accurate volatility estimations than the empirical ones. [1]
Optimizing portfolios and performance ex ante
You have developed a sophisticated prediction system based on deep learning running on a quantum computer located in the brain of the Cosmic Turtle. Every day, it generates for you, and you only, a humble vector $\mathbf \alpha\in\mathbb R^n$. Such vector contains the one-day ahead expected returns of your stock universe. What would you do?
One thing you can do is to find a portfolio that maximizes your profitability, measured in units of risk. Otherwise stated: you divide your portfolio’s expected PnL by its volatility, and maximize this ratio. If we ignore a large number of important details like execution costs, financing costs, taxation, multiperiod considerations, regulatory constraints, etc., the problem can be formulated as:
$$
\max_{\mathbf w} \frac{\mathbf \alpha’\mathbf w}{\sqrt{\mathbf w’\mathbf\Sigma_r \mathbf w}}
$$
The objective function is the Sharpe Ratio of the strategy and is a commonly used objective. It’s not always the most relevant formulation in practice, but it is one of the easiest and most insightful ways to reason about portfolio optimization. How does a factor model help? The objective function $f(\mathbf w)$ does not depend on the unit of currency: if you measure a portfolio in dollars or cents, the Sharpe Ratio stays the same; ditto if you fix your unit of currency, or scale up or down your portfolio holdings by some constant multiplier.[2] We can fix the denominator to some value–say 1–and maximize the objective, which is now $\mathbf\alpha’\mathbf w$:
$$
\begin{align}
\max_{\mathbf w}\, & \mathbf \alpha’\mathbf w \\
\text{s.t.} \,& \mathbf w’\mathbf\Sigma_r \mathbf w\le 1
\end{align}
$$
The solution is a function of the inverse of the covariance matrix (sometimes called precision matrix):
$$
\mathbf w^\star=\frac{\mathbf \Sigma_{\mathbf r}^{-1}\mathbf \alpha}{\sqrt{\mathbf \alpha’\mathbf \Sigma_{\mathbf r}^{-1}\mathbf \alpha}}
$$
And the optimal value of the objective function, the Sharpe Ratio, is $\alpha’\mathbf w^\star$ or:
$$
\text{Best Sharpe Ratio} ={\sqrt{\mathbf \alpha’\mathbf \Sigma_{\mathbf r}^{-1}\mathbf \alpha}}
$$
This highlights the importance of estimating accurately both the covariance matrix for volatility targeting and the precision matrix for Sharpe maximization, which are surprisingly related to each other.
But there are more insights to be gained by a factor model. In the formula $\mathbf r_t = \mathbf B_t\mathbf f_t + \mathbf \epsilon_t$ we did not say anything about the expected values of $\mathbf f_t$ and $\mathbf \epsilon_t$. In the remainder, we can express returns as the sum of an expected value term and a zero-mean term: $\mathbf \mu_{\mathbf f} +\tilde{\mathbf f}_t$, $\mathbf \mu_{\mathbf \epsilon} +\tilde{\mathbf \epsilon}_t$. The expected returns of my asset universe are $\mathbf \alpha:=\mathbf B \mathbf \mu_{\mathbf f}+ \mu_{\mathbf \epsilon}$. This suggests that we have some degree of freedom in choosing $\mu_{\mathbf f}$ and $\mu_{\mathbf \epsilon}$. For example, if we add a shift term $\mathbf a$ to $\mu_{\mathbf f}$ and I subtract a term $\mathbf B\mathbf a$ from $\mathbf \mu_{\mathbf \epsilon}$, the expected returns of the assets is unchanged. To remove this indeterminacy, we impose that $\mathbf \mu_{\mathbf \epsilon}$ be orthogonal to the columns of $\mathbf B$; i.e., $\mathbf B’\mathbf \mu_{\mathbf \epsilon}=0$. When we use this orthogonal decomposition, $\mathbf \mu_{\mathbf \epsilon}$ is often called alpha orthogonal and denoted $\mathbf\alpha_{\perp}$, while $\mathbf\alpha_{||}:=\mathbf B\mathbf \mu_{\mathbf f}$ is alpha parallel, because is “parallel” to the factors.
Now we replace $\alpha$ with $\mathbf \mu_{\mathbf \epsilon}+\mathbf B \mathbf \mu_{\mathbf f}$ in the Sharpe Ratio formula. To make the formulas a little simpler, we assume that all the idiosyncratic volatilities are identically equal to $\sigma$. After some matrix manipulation[3] we have a neat formula for the Sharpe Ratio:
$$
\begin{align}
\mathbf H:= & \mathbf B’\mathbf B\\
\text{Sharpe Ratio} = &\sigma^{-1}\left(|| \mu_{\mathbf \epsilon}||^2 + \mu_{\mathbf f}’ \left[ \mathbf H – \mathbf H(\sigma^2\mathbf\Sigma_{\mathbf f}^{-1} + \mathbf H )^{-1} \mathbf H’ \right] \mu_{\mathbf f} \right)^{1/2}
\end{align}
$$
Risk-adjusted performance can be decomposed into the contributions of alpha parallel, which is associated to the PnL generated by asset characteristics, and alpha orthogonal: the excess returns of assets that cannot be explained by these same characteristics and is asset-specific.
- In the limit of large idiosyncratic risk $\sigma\rightarrow \infty$, factor risk becomes neglible. The model of returns simplifies $\mathbf r_t=\mathbf \alpha+\sigma\tilde{\mathbf\epsilon}_t$. In the formula above, the Sharpe Ratio approaches $\sigma^{-2}||\mathbf\alpha||^2$. It is not surprising that factor terms do not appear in the formula.
- When idiosyncratic risk is small, SR approaches $\sigma^{-2} ||\mu_{\mathbf \epsilon}||^2$. Notice that $\lim_{\sigma\downarrow 0} SR=\infty$: if there are little excess returns that are not explainable by factors, and if most risk is factor risk, then the Sharpe can be very high indeed. This may explain why a lot of work goes into finding “alpha orthogonal.”
Understanding performance ex post
Controlling risk is nice, but having a profitable strategy is great. A habit of a highly effective trader is to revisit their historic profit and loss (or PnL), and understand its origin. Say that we have a per-period forecast of expected returns $\mathbf \alpha_t = \mathbf B \mu_{\mathbf f, t} + \mu_{\mathbf \epsilon, t}$ and actual returns $\mathbf r_t = \mathbf B (\mu_{\mathbf f, t} + \tilde{\mathbf f}_t) + (\mu_{\mathbf \epsilon, t} + \tilde{\epsilon}_t)$ such that we have expected factor and idio returns $\mu_{\mathbf f,t}$, $\mu_{\mathbf \epsilon,t}$ (note in the previous section we assumed $\alpha$ is stationary).When we look at PnL and attribution to factor returns or idiosyncratic return, we can decompose it as follows:
\begin{align} \text{PnL} =& \sum_t\text{PnL}_t \\ = &\sum_t \mathbf w_t’ \mathbf r_t \\ = &\sum_t \mathbf w_t’\mathbf\alpha_t + \sum_t \mathbf w_t'(\mathbf B_t \tilde{\mathbf f}_t) + \sum_t \mathbf w_t’ \tilde{\mathbf \epsilon}_t \\ = & \sum_t \mathbf b_t’\mathbf\mu_{\mathbf f,t} + \sum_t \mathbf w_t’\mathbf \mu_{\mathbf \epsilon,t} +\sum_t \mathbf b_t’\tilde{\mathbf f}_t + \sum_t \mathbf w_t’\tilde{\mathbf \epsilon}_t \\ \approx &\; \text{factor tilt PnL} \\ &+\text{idiosyncratic tilt PnL} \\ &+\text{factor timing PnL}\\ &+\text{idiosyncratic timing PnL} \end{align}
We encountered $\mathbf b_t \in \mathbb{R}^m$ when we estimated portfolio volatility. It is called the factor exposure vector of the portfolio. For each factor, this is the dollar-weighted sum of that factor’s characteristics. A way to see $\mathbf b_t$ is like a low-dimensional sketch of a high-dimensional object – instead of having to list the dollar positions in TSLA, AAPL, and GME, which would be tedious and non-insightful, you can just tell people at a cocktail party that you are long tech (i.e., have more long positions than short positions in tech stocks) and that you are also long meme stocks (or at least, read the room before giving an unpopular answer).
The first term is the PnL accrued from leaning(or tilting) into factors that have non-zero expected returns. The second term is similar, but for expected idio returns. The last two terms denote timing skills. Why timing? Because in order to have positive timing PnL we need to guess the signs right – we should have positive exposure to a factor with positive returns and negative exposures otherwise. In other words, the covariance covariance between factor exposures and factor returns is positive. Here is a precise statement for factor timing (idio timing can also be stated similarly):
\begin{align} \sum_t \mathbf b_t’\tilde{\mathbf f}_t =& \sum_t \sum_i b_{t,i} \tilde{f}_{t,i}\\ =& T\sum_i\frac{1}{T} ( \sum_t (b_{t,i} \tilde{ f}_{t,i} -E[b_{t,i}] E[\tilde f_{t,i}])) \\ =& T\sum_i \text{cov} (\mathbf b_{\cdot,i}, \tilde{\mathbf f}_{\cdot,i}) \end{align}
The factor timing component is the sum of the time-series covariances of exposures and centered factor returns. It should not come as a surprise that the timing PnL is almost always negligible in the long run unless you have the cosmic turtle on your side.
Further Reading
We have scratched only the surface of this topic. For example, we have not at all covered the estimation problem, and the connection between generalized linear models and alpha research (aka The Brain of The Cosmic Turtle). For the interested reader, here are a few useful references, in increasing order of complexity:
Advanced Portfolio Management by Paleologo. Wiley (2021)
Factor Models of Asset Returns by Connor and Korajczyk. Encyclopedia of Quantitative Finance(2010)
Portfolio Risk Analysis by Connor, Goldberg and Korajczyk. Princeton University Press (2010)
Statistical Foundations of Data Science by Fan, Li, Zhang, Zou. CRC Press (2020)
Spectral Analysis of Large Dimensional Random Matrices by Bai and Silverstein. Springer (2017)
Notes
- Here is a pathological example: Choose a test portfolio $\textbf w$ that is orthogonal to each vector of historical returns $\textbf w’\textbf r_t=0$ for all $t$. Such portfolio is guaranteed to exist because the number of periods used from estimation is 250-500), much smaller than the number of assets (>1000). It follows that the predicted vol using the empirical covariance matrix is 0, because $\textbf w (\sum_t T^{-1}\textbf r_t\textbf r_t’) \textbf w=0$. This a serious underestimation of risk.

- The Sharpe Ratio is homogeneous of degree 0: for any positive number $a$, it is $f(a\mathbf w)=f(\mathbf w)$.
- To derive the result, use Woodbury’s identity for matrix inversion. Note that even if individual idiosyncratic volatilities differ so that $\mathbf \Sigma_\epsilon \neq \sigma^2I$, this still provides a computationally efficient way of inverting the estimated covariance matrix as long as $\mathbf \Sigma_\epsilon$ is diagonal.