In Trading, Machine Learning Benchmarks Don’t Track What You Care About
Doing good work at HRT means constantly learning and improving. As part of that ongoing education, many people at HRT follow academic research – whether to keep up with the latest developments in their field of study, or to keep abreast of developments that can be useful to our work. To share and discuss new research with each other, we host a biweekly Paper Survey Club, where HRTers (or external guest speakers) present what they are excited about to their peers. Sometimes, these are papers about quantitative finance (for example, derivative pricing theory or portfolio construction), but for members of the HRT AI Lab we are particularly interested in papers in the fields of machine learning, optimization, and optimal control.
Many AI practitioners follow the latest academic literature too. Indeed, we are often asked if a cycle of reading and applying the latest results is a big part of our work. In practice, it is rare for us to read a paper and immediately apply it to our problems. Some of the biggest papers in these fields in recent years have a strong emphasis on empirical results rather than theoretical, and the empirical results are never going to be obtained on the exact problems we try to solve at HRT – an incremental 0.1% improvement in the accuracy of a neural network’s ability to distinguish dog breeds might not translate to predicting the price of a stock. As a result, we tend to evaluate papers on slightly different dimensions than an academic conference reviewer might – namely simplicity, reproducibility, and generality.
Simplicity
Our researchers are constantly pushing the cutting-edge to discover new ways of understanding and trading in highly-competitive markets. While a large degree of technical and mathematical sophistication is needed, the systems we build also need to be robust and maintainable. One principle we apply to achieve this is always using the simplest possible approach that achieves the desired outcome. For example, if a linear model is as good as a random forest model, we’d prefer the linear model. It is interesting to contrast this principle with the incentives in academic machine learning research. An empirically-driven paper is more likely to be published if it demonstrates novelty – but often when one optimizes for novelty, the results can be complex, which may make it less appealing in an applied setting.
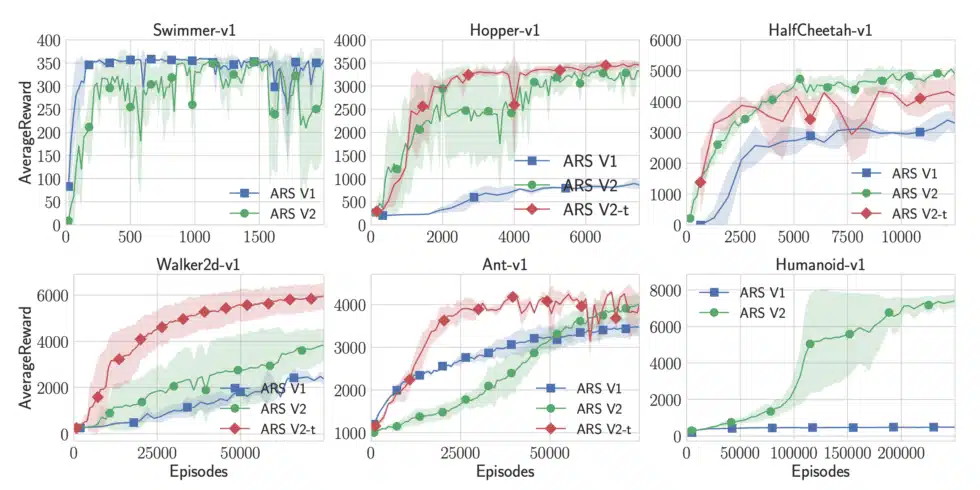
This problem is not unknown in academia and some researchers have demonstrated that if one considers many standard benchmark tasks with an eye towards the simplest possible solutions, one can find very simple and robust results. This was memorably demonstrated by the paper “Simple random search provides a competitive approach to reinforcement learning” by Mania, Guy, and Recht. The paper is concerned with control problems, like teaching robots to walk, and is interested in learning controllers in a “model-free” way – the mechanics of the robot don’t need to be explicitly modeled, and the controller must learn to go from observations to actions based only on a “reward” signal for desirable behavior. In recent years, many researchers have used model-free reinforcement learning to solve a variety of problems, including achieving super-human performance in many games. These techniques are difficult to apply in practice for a variety of reasons, of which the authors address two: the amount of data it takes to learn good controllers, and the difficulty of picking and tuning the learning algorithm itself. Additionally, the authors observe that these difficulties amplify one another: in an effort to reduce the amount of data required, algorithms have been getting more complicated and less robust.
To cut through the noise, the authors “aim to determine the simplest model-free [reinforcement learning] method that can solve standard benchmarks.” They do this in two ways. First, they demonstrate that a simple linear mapping can achieve performance on these control benchmarks as high as any result obtained with far more complex and expensive neural networks. Second, they learn this linear mapping with a lightly augmented version of “random search.” Random search, in this context, means making many slight variations on the current controller, recording how well each variation does, and then updating the controller to be more like the variations that did better and less like the variations that did worse. This algorithm can be fully described very succinctly, and as each variation can be tested independently, the algorithm is inherently parallel and efficient.
The authors don’t claim that this very simple approach is sufficient for all control problems, but that these results demonstrate that the benchmarks commonly used in academic research may not have all the properties we would want them to have if we were hoping to generalize the results to other settings (see “Generality” below for more on this topic). This paper also demonstrates that we should hesitate before reaching for complex cutting-edge methods when there may be much simpler approaches available.
Reproducibility
One benefit of “simple” approaches is that they are often easier to reproduce. This is both reproduction in the sense of “I can get the same results as this paper on the same problem,” and in the sense of “I can implement this method in the context of my problem.” As the above paper by Mania et al. describes in its introduction: “… studies demonstrate that many RL methods are not robust to changes in hyperparameters, random seeds, or even different implementations of the same algorithms… algorithms with such fragilities cannot be integrated into mission critical control systems without significant simplification and robustification.” If one can’t even be sure that a paper will be reproducible on a near-identical problem, why should one of our researchers spend their time trying to apply that result to a substantially different one?
We confront this in our own day-to-day work: a common problem for us is trying to understand how well a change to our trading might perform in the future. We can attempt to estimate that by testing how it might have done in the past. There are myriad things that can go wrong doing so, but even those aside, we still have the issue of statistical power. Not only is it remarkably difficult to avoid systematic biases, but it is easy to lie to ourselves while resolving small differences in our low signal-to-noise domain. This is somewhat similar to the problems faced by academics proposing improvements to reinforcement learning algorithms. RL methods are randomized and performance can vary widely between runs, and there is also the problem of any randomness in the benchmark tasks themselves. At the same time, running these RL experiments is computationally expensive, especially for academics with limited compute resources, and there is no standardized way to report metrics (unlike the standardized ways we run ‘backtests’ internally for our changes).
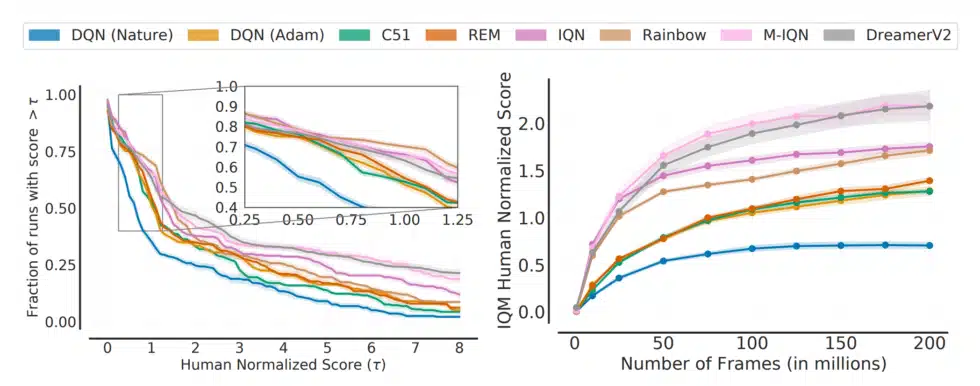
This problem is quantified in the paper “Deep Reinforcement Learning at the Edge of the Statistical Precipice” by Agarwal et al. The focus of this paper is not strictly about the difficulties in mechanically reproducing a result, but more about how those results are communicated. The authors demonstrate that the often-reported point estimates of performance on various benchmark tasks are very misleading since the level of uncertainty in these metrics is substantial. Furthermore, subtle differences in the exact evaluation protocol can completely invert results. For example, they find that in a benchmark based on Atari games, one algorithm’s reported result is most likely better than another just due to this variability. In other cases, if the evaluation protocol for one paper is applied to another, any gap in performance goes away or even produces opposite conclusions. Unfortunately, there is no easy solution proposed for this problem: researchers should strive to make the uncertainty in their results as clear as possible and use standard metrics, and reviewers should hold them accountable. For the practitioner, one needs to apply a heavy degree of skepticism to any new result, and to prefer methods that have robustly demonstrated their reproducibility wherever possible.
Generality
As we mentioned earlier, the majority of AI research is empirically driven, but the empirical results may be obtained on problems that are too different from our own to be immediately applicable to us. For example, it’s not obvious from first principles that predicting future stock prices from market data as a regression problem is equivalent to image classification or machine translation, so should a new type of model evaluated primarily on those tasks be expected to do well on our problems?
Consider the problem of designing a deep learning model optimizer. There is an ever-growing zoo of optimizers designed for deep learning problems, yet actually selecting one is a fraught problem in itself. Given that theory provides little guidance for their design, one might assume that more recently published optimizers are superior to older ones, at least empirically. However, there is reason to be suspicious: optimizers have many hyperparameters, and one could perhaps inadvertently suggest a seemingly better design just by more carefully fitting these hyperparameters than the reference/benchmark optimizer. Furthermore, there is a type of publication bias at work: if, by chance, an optimizer is slightly better on average than the reference on a particular set of problem instances being evaluated, we may declare progress has been made and the paper may be published, but there is a serious risk that weak improvements will not generalize “out of sample” to other instances in the space of deep learning problems.
One paper we enjoyed that addresses this is “Descending through a Crowded Valley – Benchmarking Deep Learning Optimizers” by Schmidt, Schneider, and Hennig. They collect a set of fifteen popular (often-cited) optimizers and perform an exhaustive search over the cross-product of problem, optimizer, optimizer-tuning, and learning rate schedule. They have two particularly interesting conclusions that are directly applicable to us. The first is that the Adam optimizer (Kingma and Ba), first published in 2014, is still the best go-to optimizer for a deep learning problem – it achieves our desired property of “generality.” The second lesson is more precautionary than actionable: that “different optimizers exhibit a surprisingly similar performance distribution compared to a single method that is re-tuned or simply re-run with different random seeds.” In practice, given our finite researcher time and somewhat finite computational time, that means it is not even clear that testing new optimizers is wise unless there is something particularly unique about the intersection of the proposed optimizer and problems it claims to work well on.
Conclusion
Academic research is a critical resource for us in improving our trading. Reading the latest academic research inspires us, even when it isn’t directly applicable. We must recognize that the incentives in academic research may not be aligned with the incentives of practitioners, and so we must bring a healthy level of skepticism when considering applying this research to our problems. But part of becoming better researchers and technologists means remaining curious, engaged, and inspired by others’ work.
Learn More about HRT AI Labs [HAIL]
Hudson River Trading stands apart in the industry due to our extremely open, collaborative environment and strong common technological platform that allows us to innovate rapidly. Leveraging our substantial compute cluster outfitted with modern GPUs, and working alongside some of the best researchers and engineers in the field, you’ll push the boundary of deep learning at scale. We have a meritocratic, low-politics culture, where our researchers spend nearly all of their time on research and innovation is rewarded. Learn more about HRT AI Labs [HAIL] by visiting our new Machine Learning at HRT page.