Introduction
Throughout the summer, HRT’s Software Engineering interns worked with mentors, teams, and longtime HRTers on independent programming projects that tackled the most interesting problems in the world of automated trading, making a notable impact on our day-to-day operations.
This post in our intern spotlight series highlights the work of three of our Software Engineering interns:
- Generating Code with Code Reflection by Jacob Urbanczyk
- Heartbeat v2 by Alice Chen
- Unraveling Exception Backtraces by Isidor Kaplan
Generating Code with Code Reflection
by Jacob Urbanczyk
Intro
Trading on dozens of exchanges is challenging. Many of them use their own communication protocol formats. One laborious problem HRT faces is writing and maintaining the code interfacing exchanges. It is crucial to abstract out the common parts to avoid repetition and reduce maintenance toil.
HRT records every message it sends to an exchange for various purposes. Messages typically have an exchange-specific encoding, but often share a similar structure: a message header and payload. The header consists of information like the total message length and type.

Messages are consumed and replayed by many of our verification tools. These tools use the TripRaw library (Trip is our internal system for sending orders), which reads and dispatches messages differently based on each message and protocol type for internal processing. Since we don’t know the message type beforehand, we must first parse a few bytes, read the type, and then proceed with the parsing procedure.
This repetitive code could be avoided if we could generically infer the message type. My project involved leveraging RawReflect, our internal C++ reflection library, to find the fullest type and get rid of the repetitive part of TripRaw.
RawReflect
Reflection is a program’s ability to examine and introspect its own structure and code at run-time. RawReflect uses the program’s types to perform bidirectional conversion between a binary message’s representations and a structured object. To illustrate this, consider the following C++ struct:
struct Foobar {
int field1;
short field2;
char str[3];
};RawReflect is able to convert a bag-of-bytes representing this struct into a structured message representation:
000003E80042485254 --> Foobar(field1=1000, field2=66, str='HRT')This structured message contains all field types, names, and offsets in the struct. It exposes a convenient interface for making queries like “what is the value of the field str?”
RawReflect supports nested structs, unions, variable length structs, and automatic upcasting. RawReflect determines the most concrete type by parsing the message header and then inferring the fullest type.
Supporting RawReflect for new structs simply requires annotating the struct with a couple of preprocessor macros. The build system will do the rest by using clang to dump struct memory layouts and then auto-generating all necessary code.
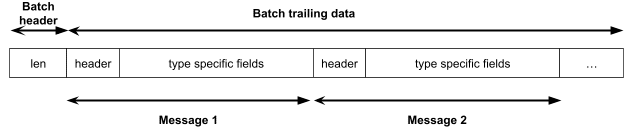
As part of my project, I worked on making RawReflect more robust. The base type that is being upcasted from can now be the first member in a struct, instead of inheriting from the base. Moreover, the trailing data of a struct itself can be now upcasted to the fullest type. This allows the trailing data to be an arbitrarily-sized batch of messages, each of a different type:
Solution
RawReflect solves the problem of finding the fullest type of a raw message in a generic way. TripRaw can take advantage of that to avoid the necessity of writing boilerplate code for each exchange protocol format.
When adding support for a new protocol to TripRaw:
- Annotate protocol structs to make it reflectable
- Dump struct layouts using clang
- Generate RawReflect and TripRaw code stubs
Steps 2-3 are done automatically by the build system. The clients of TripRaw can now use messages from the newly added protocol!
Reflection is a powerful programming paradigm that can reduce the amount of boilerplate code and thus the maintenance burden. The trade off here is the performance drop — this is fast enough for batch processing of recorded data, but not for latency-sensitive use. However, it is a perfect fit for TripRaw, and has potential for wider adoption across the firm.
Heartbeat v2
By Alice Chen
The Problem
HRT’s build and test tools spawn many child processes within a large process tree, parts of which run on remote machines over SSH. If interrupts occur while running these processes, such as SIGINTs triggered by Ctrl+C’s, we expect all processes in the process tree to receive the signal. To gracefully handle these interrupts, build/autotest installs custom signal handlers that perform cleanup tasks like generating user-friendly diff summaries. For some processes, reliably invoking these signal handlers is necessary for correctness.
If all processes are executing on the same machine, the operating system running on that host is responsible for ensuring that all processes in that process group receive the signal. However, in the case of remote processes, signal propagation over SSH tunnels is fragile, as the operating system is unable to guarantee that processes running on other hosts receive the signal properly. As a result, users might see old remote build processes lingering even after the forefront local build was interrupted, which hogs machine resources and causes unexpected side effects for developers.
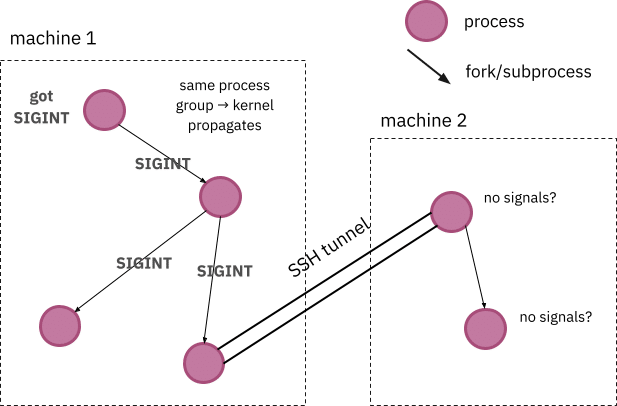
Figure 1: The difficulties of propagating signals across machine boundaries
Existing Work
Heartbeat v.1 was our first attempt to properly propagate signals through a process tree. In this version, we propagated signals by logging signals intercepted by the root process into an NFS file, which are readable across host machines. Child processes then periodically read the file to keep up-to-date and properly invoke signal handlers. Unfortunately, NFS with caching has poor consistency guarantees and the filers could become overburdened, making it difficult to ensure that the data read is fresh.
Heartbeat v.2: gRPC Heartbeat client-server
My intern project, Heartbeat v.2, eliminates the reliance on NFS and turns to gRPC as the communication mechanism between the root and all of the clients in the process tree. At the startup of a new root process, we spawn a gRPC heartbeat server alongside the root process that acts as the central authority for intercepting and tracking signals. Heartbeat clients interact with the server through protobuf ping messages:
(heartbeat.proto)
message Heartbeat {
double ts = 1;
Process process = 2;
Signals signals = 3;
string log = 4;
bool shutdown = 5;
}
message HeartbeatState {
double ts = 1;
Signals signals = 2;
}
(heart_server.cc)
grpc::Status Ping(grpc::ServerContext* context,
const heartbeat::Heartbeat* beat,
heartbeat::HeartbeatState* state) override;As seen in the HeartbeatState message above, the gRPC heartbeat server responds to ping messages from the clients with the current status of signals received.
As a nice side effect, clients can now forward messages logged in their process to the root server, which aggregates all messages into a single, unified log.

Figure 2: Heartbeat v.2’s high level design
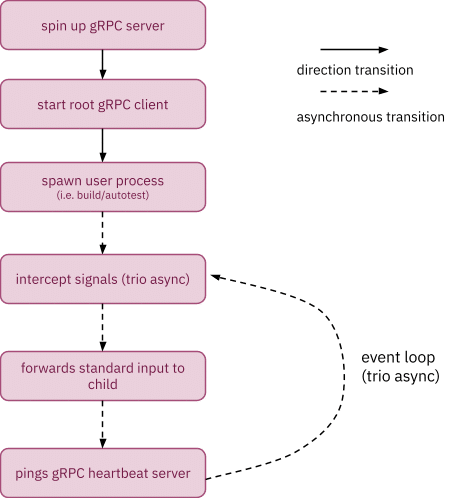
Figure 3: Control flow of Heartbeat v.2
As seen in figure 2 above, each Heartbeat v.2 child process starts its gRPC client in a separate heartbeat thread, which periodically pings the heartbeat server to obtain the most recent state of signals; if there are pending log messages, the client will piggyback the new log messages along with the ping. After receiving a response from the server, the heartbeat thread checks if any new signals have been received, and throws any new signals back to the main thread’s handlers.
Integrating Heartbeat v.2 into HRT’s build and test tools is very non-intrusive and transparent to the user since it only requires exec-ing the server/clients alongside the build/test processes in the tree. The users are able to run the same commands as before, and automatically enable Heartbeat v.2 under the hood, giving them the benefit of better signal handling at essentially zero cost.
Unraveling Exception Backtraces
by Isidor Kaplan
Background
C++’s exception handling is not traditionally celebrated for its user-friendly interface, particularly when compared to languages like Python. At Hudson River Trading, developers extensively use exceptions in non-performance-critical paths, and the minimal information available when an exception is thrown often costs us time in the debugger. An experience more like Python’s, where an uncaught exception shows the source locations of each frame it passed through, would make many more problems diagnosable at a glance.
Recently, it was proposed for C++ standardization that the catcher of an exception should be able to request that a stacktrace be included with it; the proposal included sample code showing how to achieve this on current C++ implementations. HRT recently adapted this logic for internal use, but uptake has been limited since our facilities for displaying the resulting backtraces were fairly primitive. This summer, I overhauled HRT’s backtrace library, significantly enhancing HRT’s workflow concerning exceptions.
Backtrace Improvements
During my internship at HRT, I overhauled the internal backtrace framework to provide a modern interface to fetch binary names, symbol names, source code locations, and snippets from captured frame pointers. The updated product supports different levels of granularity and works with the internal exception class. As a result, developers have a better experience when debugging production issues.
The backtrace library serves three main use cases:
- Resolving and printing exception information upon request from C++ inside a catch clause (screenshot below)
- Providing full context from the std::terminate handler
- Propagating C++ backtraces into Python when the exception crosses the boundary (we extensively call into our C++ code via Python bindings)
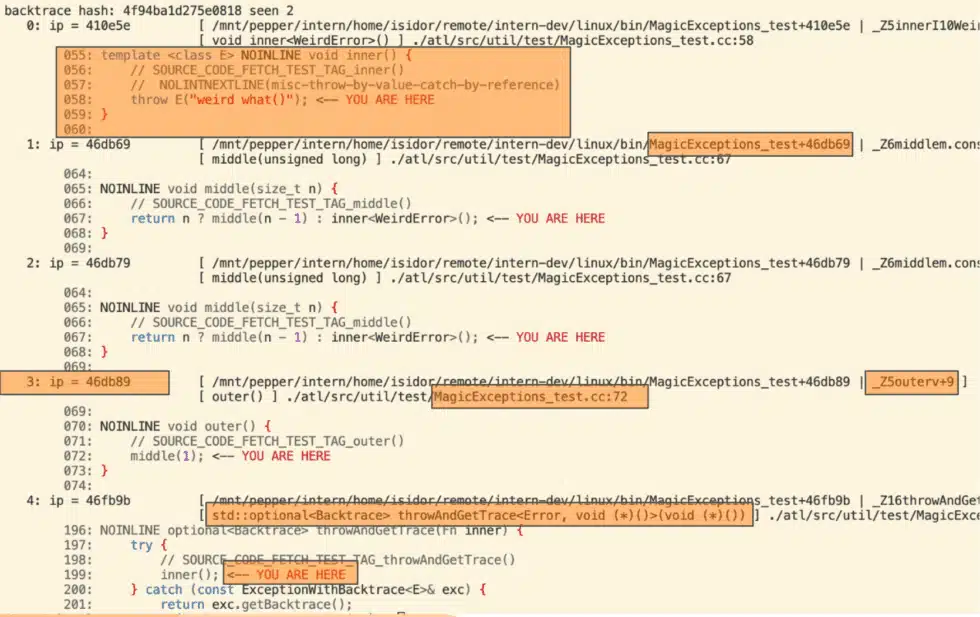
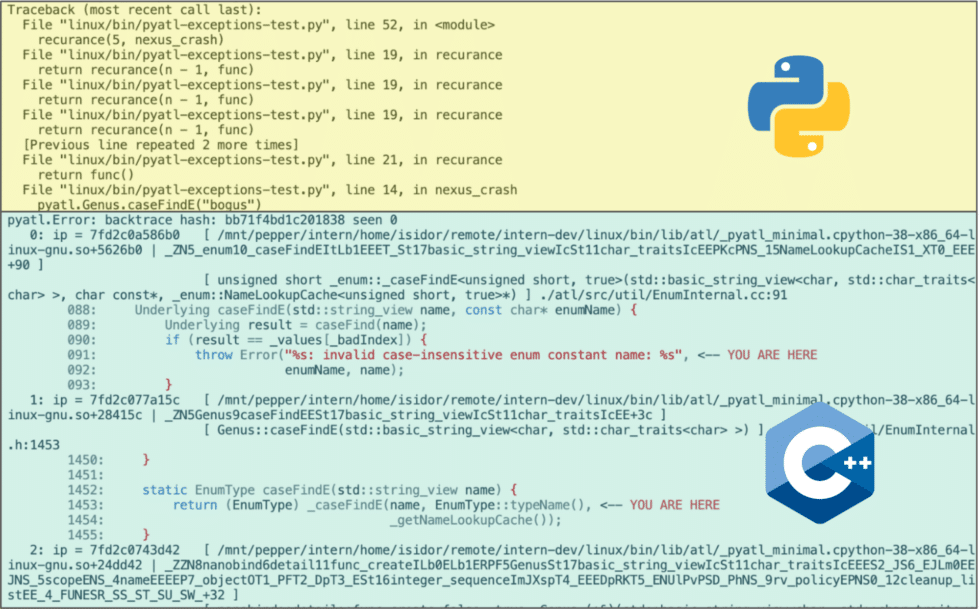
Balancing information granularity and performance overhead is vital in high-performance systems. The tool supports various detail levels, manually specified or implied based on environment considerations. At a minimum, it decodes an instruction pointer into a binary+offset pair so that we have enough information to resolve symbols later, even when using dynamic linking (mostly relevant for the Python-bindings case). In critical systems, this is the sole computation, deferring the more time-consuming parts for after-the-fact computation using an internal tool analogous to Linux’s decode_stacktrace. In less latency-sensitive contexts, more data can be shown to reduce debugging work, which involves reading the binary’s debug symbol table to identify symbol+offset and function location. Taking a step further, we may locate the file:line in the source code. These operations have similar overhead and are tolerable outside critical paths. We may also include actual source code in the output to provide developers with more insight without external tools. However, loading large source files from network-attached storage can be slow for live execution processes, so we only print this information when the process will terminate or if the caller is from Python, where performance is less critical.
Moreover, to allow Python users calling C++ to get meaningful exception messages, I modified nanobind and pybind11 to capture the C++ stacktrace using the previous primitive and attached it to the converted Python exception. The wrapped Python exception by default only includes frame pointers, and the symbol lookup is deferred until printing the exception.
Other challenges involve optimizing performance through caching, handling network storage, and taking care of missing sections of DWARF or symbol table. With everything addressed properly, developers at HRT may now spend less time loading core dumps or guessing the source of C++ exceptions from Python messages.