Introduction
Summer is intern season at HRT; within a few short months, our interns are truly woven into the fabric of HRT’s culture, adding vibrancy and enthusiasm to our offices around the globe. Working in close collaboration with a supportive network of mentors, teams, and longtime HRTers, interns have the opportunity to tackle some of the most interesting technical problems in the world of automated trading and make a profound and lasting impact on our day-to-day operations. Throughout this past summer, interns and HRTers connected with each other over a jam-packed events calendar, shared projects, and extra-long lunch lines in our cafeteria.
This post in our intern spotlight series highlights the work of three of our Software Engineering interns:
ToucanServer
By Emma Yang
Over this past summer, I’ve had the amazing opportunity to learn about the engineering problems HRTers are tackling and work on a few projects of my own as a Core intern. One of my projects was ToucanServer, a gRPC and protobuf-based server that expands upon HRT’s manual trading (“click trading”) platforms.
The Problem
While most of HRT’s trading is wholly automated, the amount of non-automated trading has increased as the company has expanded. To that end, it has become increasingly important to support manual, human-driven trading that allows HRTers to intervene and send orders and cancellations to markets.
HRTers currently use Toucan, a command-line interface, for manual trading. However, as more and more teams at HRT need a way to manually enter orders, we increasingly need a more versatile tool that can be adapted to the way different teams at HRT trade.
ToucanServer
My project was to develop a gRPC server that would expand Toucan into a more flexible platform for manual trading that would expose clients (whether it be semi-automated trading strategies or HRTers opening a custom front-end interface for their team) to the order entry, state management, and position-tracking features of Toucan.
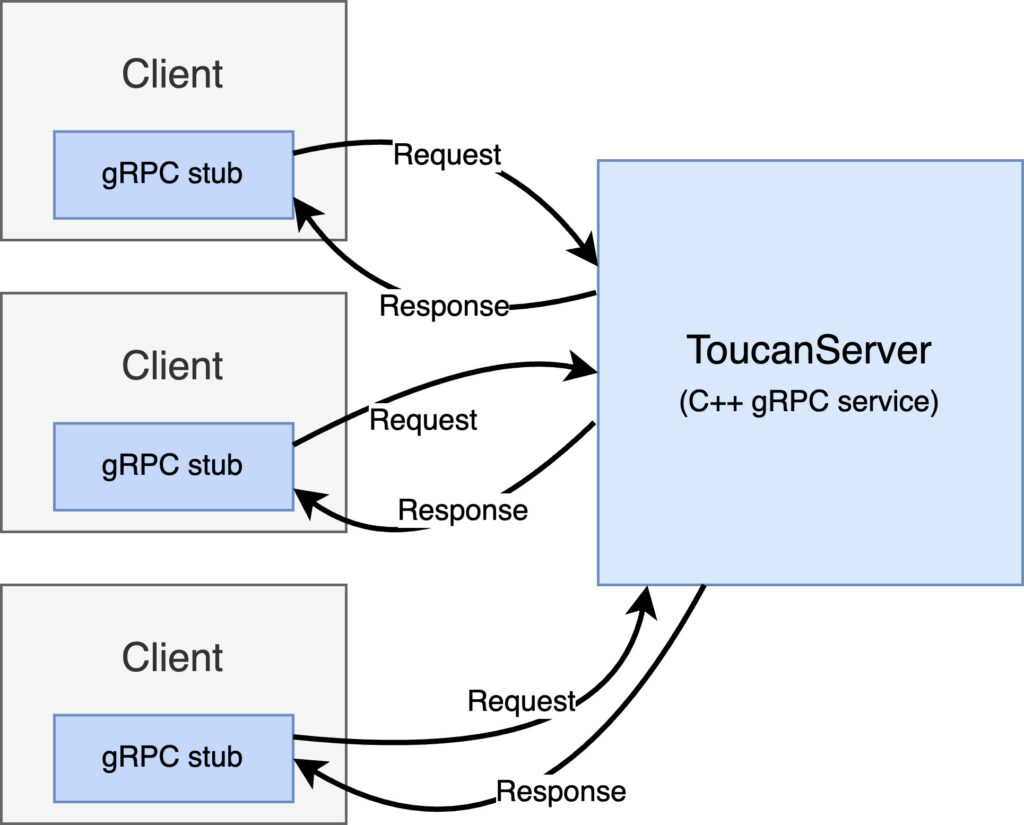
Implemented in C++, ToucanServer synchronously handles unary and server-streaming remote procedure calls (RPCs) from connected clients to send orders and cancellations.
Clients communicate to ToucanServer by instantiating a gRPC stub — a local object in the client program that allows a client to send requests and receive responses defined in a protobuf specification using methods implemented in the gRPC server. This client-server model makes sending orders and receiving status updates from ToucanServer very intuitive for users building clients for manual trading, as the client can make remote calls to ToucanServer just like calling a local method.
Multithreading in ToucanServer
One of the main technical challenges of building ToucanServer was the use of multithreading. While most of HRT’s infrastructure avoids multithreading due to the overhead of context switching, a service like ToucanServer needs to run a concurrent thread so that the server can listen and respond to client requests. In ToucanServer’s case, since I used a synchronous server model, this thread will block whenever we receive a client request and unblock when the server returns a response.
To communicate between the main thread for order entry and the server thread, ToucanServer uses a thread-safe queue of requests for order entry and status responses from clients. Inserting a request into the queue blocks the server thread with a client-specific mutex, waiting until the request has been processed by the order entry thread and passing the result back to the client before processing any additional requests from that client.
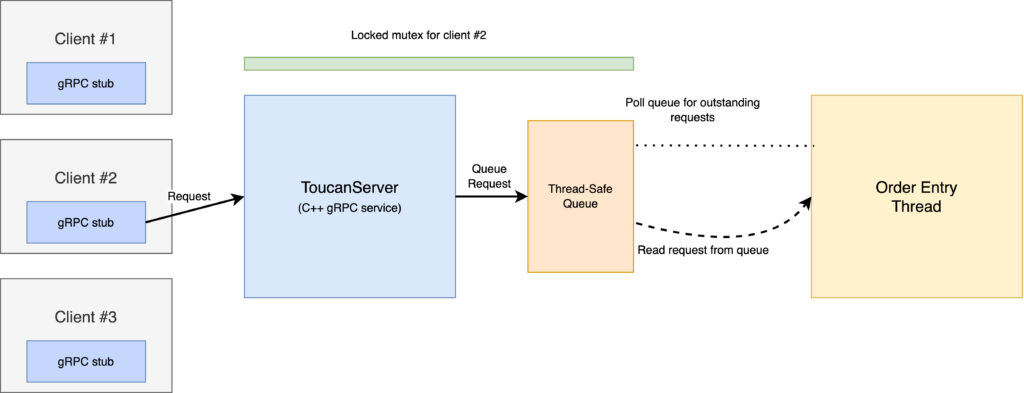
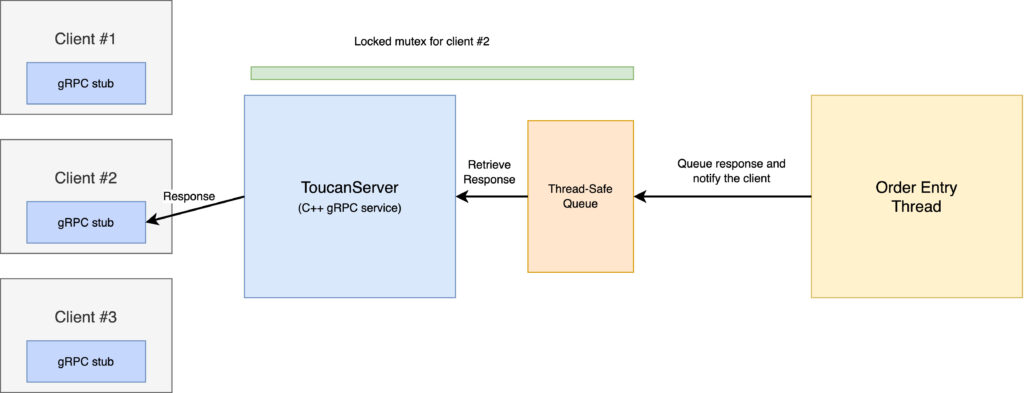
Not only does this multithreaded design enable us to run a synchronous server concurrently with the order entry thread, it also enables us to expand Toucan from a single-client-per-process tool to a single process that can handle multiple clients at once. Since gRPC automatically multiplexes client requests across its own thread pool, ToucanServer can handle both concurrent clients and concurrent client requests.
Impact
ToucanServer’s main purpose is to enable trading teams to build web apps and other front-end interfaces that connect to ToucanServer, send instructions through RPCs, and display the information contained in status updates that are streamed to the client. Each team will have the flexibility to build an interface based on the view of order state that is most useful to them – a significant unlock for our manual trading platforms.
Cashy S3 Integration
By Eric Zhang
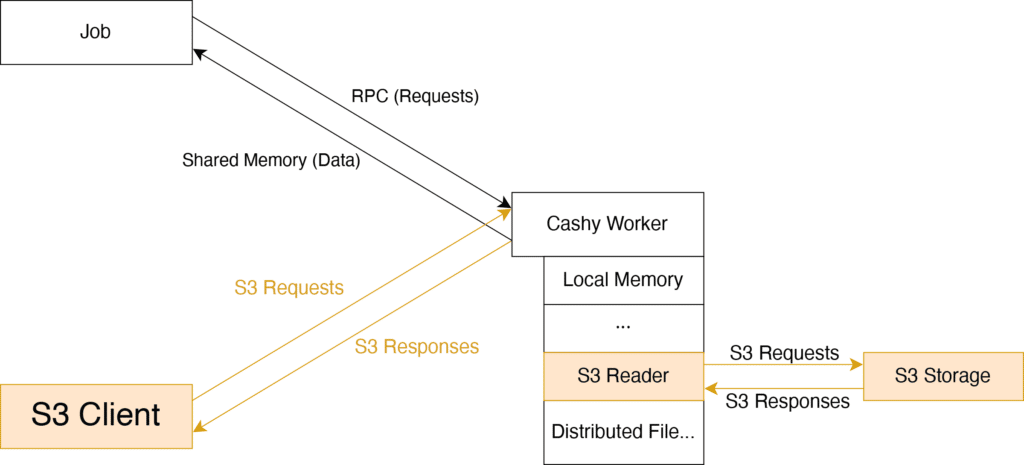
For high-performance applications, data needs to be close to where it’s processed. HRT achieves this through Cashy — a distributed cache that enables rapid data retrieval with high scalability for compute cluster applications. Cashy utilizes a hierarchy that ranges from local memory to remote solid state drives, with many layers in between, and acts as a proxy client to a distributed file system for reads at significant scale.
To make a request, applications make a remote procedure call to a Cashy daemon on the same machine. That local Cashy process turns a single request into many block requests, which it sends to many other caching hosts in parallel. Finally, Cashy returns the response over shared memory, allowing it to rapidly service requests.
Cashy’s default configuration is typically used for servicing NFS read requests, however, many applications use object stores like Amazon’s Simple Storage Service (S3). In this project, we extend Cashy to serve requests in the S3 format and read from S3 stores. This allows applications that use S3 to be able to run at scale in our compute clusters.
S3 Server
One simple way to serve S3 requests is to set up HTTP servers that are Cashy clients and proxy the requests from S3 clients to Cashy. However, this creates performance overhead due to extra interprocess communication and requires additional deployment and monitoring.
Instead, we implement a subset of S3 functionality in Cashy itself. Since the Amazon S3 API is large, we start by only implementing the GetObject action, which retrieves S3 objects.
GET /file.txt HTTP/1.1
Host: somebucket.somehost.com
Date: Mon, 3 Oct 2022 22:32:00 GMT
Authorization: authorization stringAmazon S3 GetObject request
All other actions can be handled by a slower, but fully-featured S3 implementation without much performance loss.
Since Cashy operates in an asynchronous model, all networking is done using non-blocking sockets controlled by an epoll-based event loop. To perform a GetObject, a Cashy worker process begins by receiving an HTTP S3 request. This S3 request is then translated by an S3 parser into a Cashy request.
Once Cashy receives the request, it translates the object read request into multiple block requests. As an optimization, Cashy prefetches blocks so that they will be preloaded into faster tiers of storage hopefully before the client asks for them. One tricky corner case is that for many S3 reads, the file size is unknown. Therefore, we always prefetch at most the number of blocks that have already been read, to avoid prefetching more than twice the number of blocks necessary.
Earlier we mentioned that S3 actions other than GetObject will be handled by a different, fully-featured S3 implementation. Therefore, the Cashy S3 server needs to redirect requests it can’t handle. Despite what the Amazon S3 documentation states, S3 clients like Boto3 do not properly support HTTP redirects. To work around this, we built functionality for the Cashy S3 server to proxy S3 requests. Here, we had to be careful to re-authenticate the requests because the host has changed (see Amazon Signature V4).
S3 Reader
Now that applications can use the S3 protocol to read from Cashy, we’d also like Cashy to read from S3.
Our S3 reader needs to support the following interface:
// IReadCashyBlocks impl ---------------------------------------------------
void beginReadBlock(BlockReadInfoPtr blockInfo) override;
void cancelReadBlock(const BlockReadInfo& blockInfo) override;
using CashyReadBlockCallback = Callback<void(BlockReadInfoPtr blockInfo)>;
---------------------------------------------------A CashyReadBlockCallback is expected for each beginReadBlock that has not been canceled.
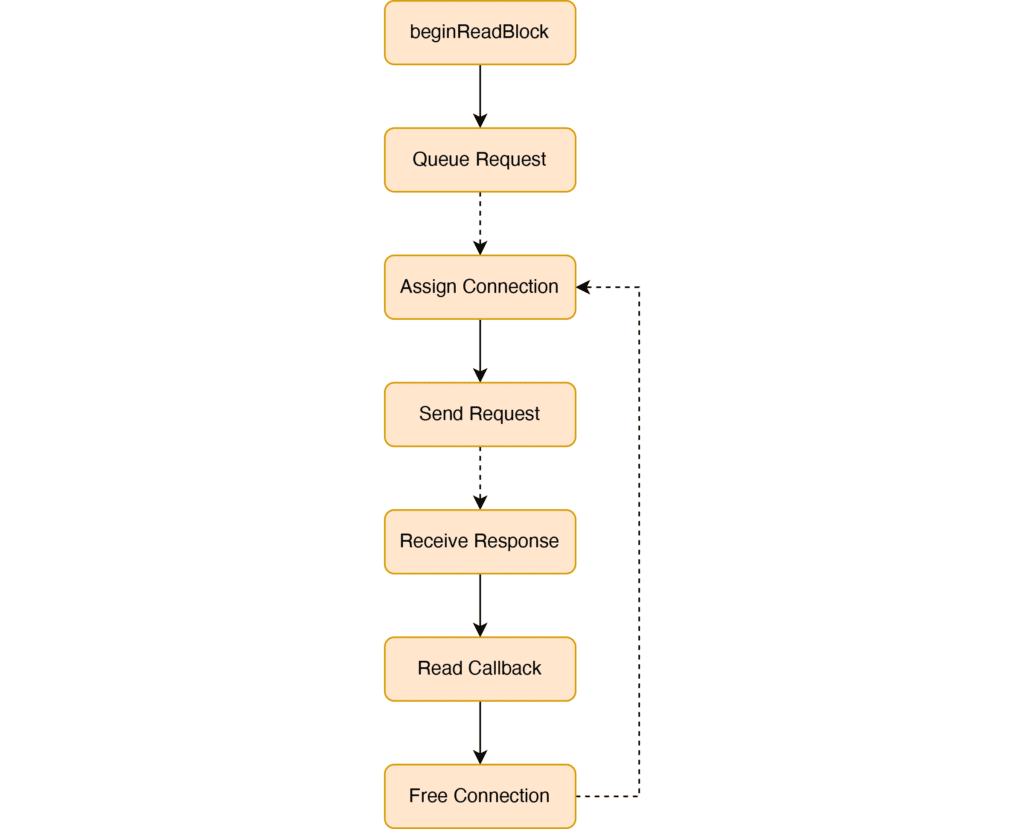
To implement this efficiently, each Cashy worker has a connection pool for each S3 host that Cashy can retrieve information from. Requests wait in queue until a connection to the corresponding host becomes available. Then, we send the request, wait for a response, and perform the read callback. All of this is done asynchronously to avoid blocking.
Overall, the state machine roughly looks like:
Conclusion
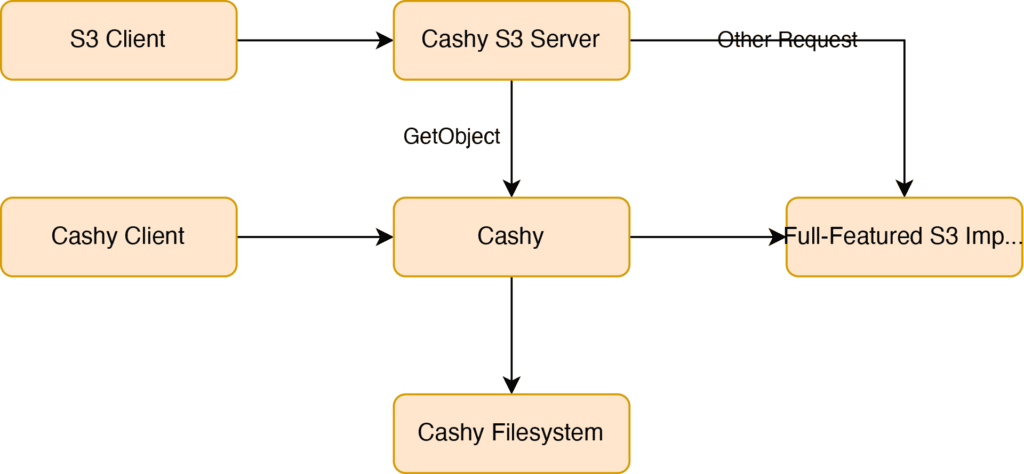
Before, Cashy could only support the following flow:

Now Cashy supports clients using S3 to read from Cashy’s underlying filesystem. Moreover, existing Cashy clients can now read from S3 stores.
Given that Cashy can both serve and read from S3, we can also now use Cashy as a high-performance cache for S3 services!
Labshell
By Shahbaz Momi
Imagine that you want to set up a live trading environment that relies upon dozens of configuration files and just as many, if not more, binaries running across several hosts. Now imagine you want to interact with this environment, swapping out these binaries in real-time and changing configuration on the fly. How would you approach this problem?
HRT has rolled out its own testing framework called Labtest which attempts to solve this issue, but it has some shortcomings; namely, it doesn’t have the interactivity desired as it only supports automated, closed-loop testing. My first project over the course of my summer internship at HRT was to develop Labshell, an interactive shell that aims to fill in this gap.
Architecture
Labtest contains lots of features around deployment and configuration. However, it doesn’t provide any means of interactivity; it is a run-once style of program, and this comes with a few challenges, specifically around architecture. While minor changes to the environment can be made (e.g. restarting a process), major changes such as restarting processes on different hosts require tearing down the whole environment. To account for this, I chose to use an immutable data flow architecture with a central render loop passing data in one direction, allowing for effective handling of both types of changes.
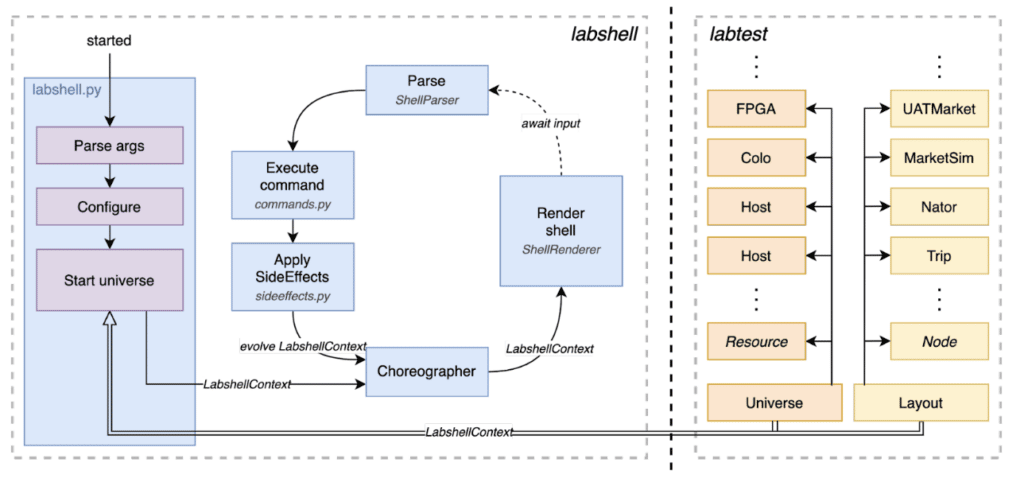
Minor changes can be performed directly, while major changes are collated and executed in batch by the Choreographer at the end of the cycle. Immutability is important here so that the currently running environment can’t be modified, but rather has to be evolved for a major change.
Concurrency
To achieve interactivity, we need a separate UI thread which is never blocked and ready to receive user input. In isolation, this is easily solved by simply creating a new background thread. However, we also have to communicate with Labtest threads running background jobs (e.g. sending keepalives to remote hosts, running processes, etc.) while managing cancellations and exceptions that occur in these jobs. The solution that Labtest internally employs is to use Trio, a Python library for async concurrency. With Trio you can create tasks which are essentially coroutines running on a single thread (to get around GIL limitations). We can leverage coroutines to have the small, periodic tasks that Labtest needs to schedule run on the same thread as the UI thread, avoiding any concurrent read and write issues.
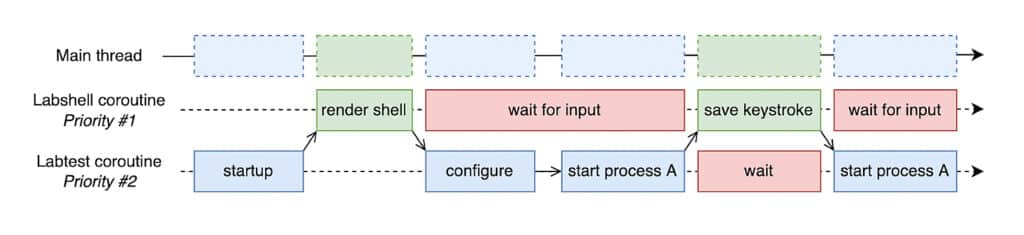
Note that certain tasks, like creating a new process, actually create new threads internally — trio manages this for us by creating thread-safe communication channels and managing the thread’s lifetime.
User Interface
The user interface is perhaps the most important part of this project; how do we develop something efficient that people actually want to use? Throughout the design and creation of the UI, this was facilitated by a number of key features. The UI framework I used to render the shell was prompt_toolkit, an excellent library which made it easy to facilitate these features while also being aware of the hidden challenges mentioned above.
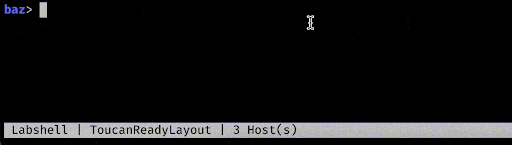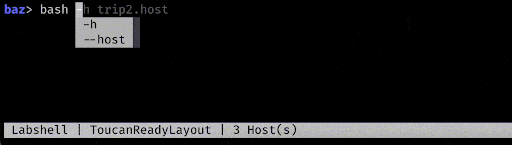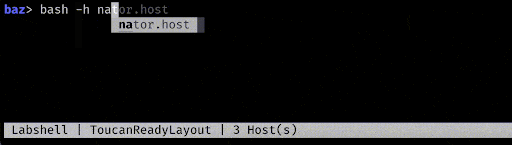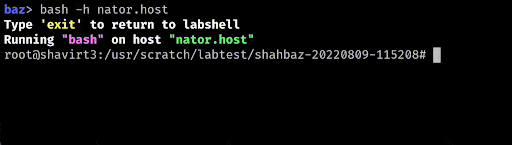
Autocompletion
Autocompletion is probably the largest time saver, but with it comes a number of other questions, such as how to generate these completions, how to order the completions, and how do they evolve as the user types in additional input?
Inferencing
If a user doesn’t have to type input, why should they? This is another huge time saver, as this means the user can omit many parameters to commands.
# A command which accepts 2 parameters: command param_1 param_2
# param1 = ["option_1"], param2 = ["option_2", "option3"]
# All of these are valid since we can infer param_1:
command option_2
command option_1 option_3
# Invalid since we can't infer param2:
command
command option_1But it also comes with its own considerations like identifying sensible defaults, and addressing how to handle cases where multiple inferences are possible.
Conclusion
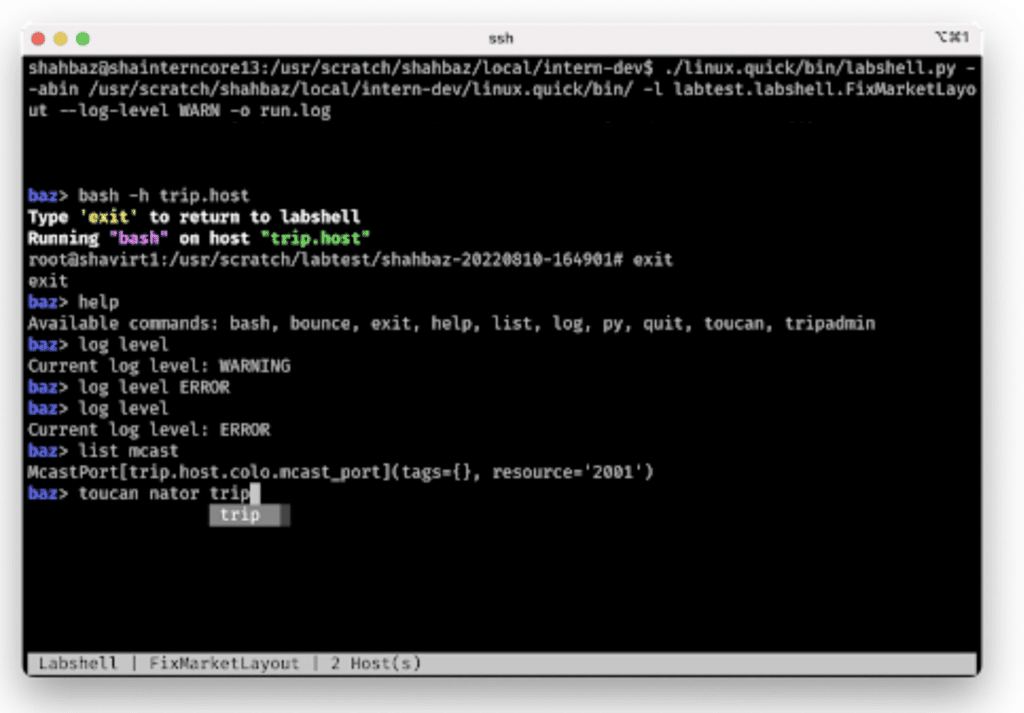
In the end, I had a shell which was able to start bash and SSH sessions into remote hosts, reconfigure the live environment, restart and debug running processes, and launch our internal tooling preconfigured to the simulated trading environment.
Like what you see?
If you find the featured projects exciting, consider applying!