Introduction
Field-programmable gate arrays (FPGAs) are increasingly used in the areas of finance and trading. They allow the user to create custom hardware without many of the costs and delays associated with building custom chips. FPGAs can be used to reduce latency, handle data bursts more effectively, and decrease system complexity (among other things).
Building FPGA systems requires the application of various disciplines. Broadly speaking, these can be divided into design and verification, which is to say, the construction and testing of an FPGA design respectively. And while it is important to test all of a system’s functionality, it is perhaps doubly so for hardware, which has the additional complexity of parallelism on a scale generally not encountered in the software world. This makes it susceptible to timing problems (both internal and external), which must be tested to gain confidence in the device.
This post will describe our verification environment and how we arrived at where we are today. We’ll start by laying out the goals we have for our environment. Next, we’ll discuss different approaches to the problem, and describe how we have built out our environment to reach our goals.
Environment Goals
There are a lot of choices when it comes to building a verification environment, so it’s worth considering what properties we’d like ours to have. Establishing functional correctness is clearly the top concern. The hardware we build is a part of numerous trading systems in the firm and interacts with many different exchanges and marketplaces throughout the course of any given day. This means that verification not only determines that a device is behaving as intended, but also that it abides by HRT’s risk checks, and follows all rules and regulations.
Not only do we need to build tests to verify correct behavior, we also want to create an environment that makes it easier to do so. Certainly everyone wants to maximize developer productivity, but it’s especially important for us as trading is particularly time-to-market sensitive. This is also just good sense. Who doesn’t want to work in a system that makes it simpler to express what you want to do?
One of the ways we want to make verification developers more effective is by reusing code whenever possible. HRT develops code in C++ and Python, which interacts with all the same markets as our FPGAs. If we can put that code to use in the context of verification, we’ll not only save time, we’ll save ourselves from bugs introduced during a second implementation.
We also want to be able to quickly find problems when they arise. Of course, this must happen before deploying new hardware for trading, but it is also good to find bugs as soon as they are introduced into the codebase. Latent and/or unresolved bugs only compound our problems as new code is built on broken code.
Finally, we want to make use of the computational resources we have at HRT. All of the testing in the world won’t help us if those tests aren’t frequently executed.
Different Approaches
Given our goals, we can then apply them to various verification methodologies. Perhaps the simplest approach is to use test vectors. Test vectors provide a list of primary input values and expected primary output values over time. They are essentially time series truth tables. As a trivial example, a JK flip-flop could be tested as follows:
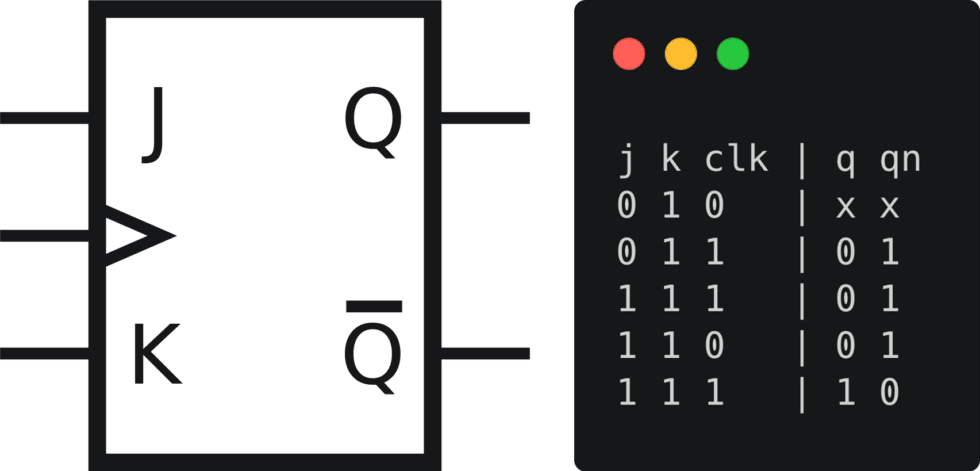
Test vectors are still used today during some stages of chip manufacturing, however, for our purposes this approach is far too fragile. Parallel interfaces are difficult to deal with as the entire device is treated as a whole. And debugging is especially painful with all context removed. We might see that an output is different than expected, but why was it expected and what does it mean that it’s different? Lastly, this approach does not allow for the possibility of multiple correct results. While it is possible to be fully predictive about the behavior of the device given sufficient information about low-level implementation details, requiring that level of knowledge will greatly limit the abstractions we can use when building tests.
Another approach that is still more widely used is HDL (hardware description language) testbenches. We use Verilog at HRT (or rather SystemVerilog), so given a tool that can simulate Verilog it’s possible to just write more Verilog to stimulate and check the design. For example, we could verify that JK flip-flop like so:

Since Verilog was built as both a hardware design and verification language, this seems like a potentially reasonable path. However, we would far prefer to use languages that are already established at HRT such as C++ or Python for our testing. Doing so allows us to achieve our goal of code reuse. But beyond that, these languages are far more expressive and supported than Verilog. While the addition of SystemVerilog brought numerous language features such as associative arrays and classes, it’s hard to beat modern C++ or Python. And since the use of software languages far outstrips HDLs, it’s no surprise that tools like debuggers and profilers, as well as community support (e.g. Stack Overflow), are much better for C++ and Python than for Verilog.
The Universal Verification Methodology (UVM) is currently a particularly popular approach. This is a class library for SystemVerilog which implements common verification concepts such as drivers and monitors for marshalling transactions onto and off of hardware interfaces. Since this is built on top of Verilog, all of our objections to Verilog testbenches still apply. So while we don’t use UVM, we do borrow heavily from its concepts as there’s no reason they can’t be implemented in other languages.
For our purposes, we use co-simulation, which leverages foreign function interfaces (FFIs) to communicate between HDL simulators and code written in other languages. Usually this is with C, but it is fairly straightforward to build up from there to C++, Python, or most other languages. Verilog has two FFIs: the Verification Procedural Interface (VPI) and the Direct Programming Interface (DPI). DPI is more streamlined, whereas the VPI provides the ability for design introspection, interaction with simulator internals, and many other features. However, both enable interaction with non-Verilog code. This checks a lot of our boxes, as we now have flexibility to choose the best language for the job and to recycle as much code as possible both from other HRT developers as well as the open source community. We think this makes a lot of sense because it only uses the simulator for simulating Verilog and leaves the business of testing designs to systems which are often better equipped to do so.
Tools We Use
After deciding that co-simulation is the way to go, we still have to build out the environment. We do so using a combination of open source and home grown technologies.
Cocotb is an open source Python package which enables access to signals inside of the simulator from Python. It is simulator agnostic, so tests are portable if different tools are needed. It also supports Verilog and VHDL, though we only make use of the former. And it provides a coroutine scheduler for dealing with the parallelism inherent in hardware designs. Coroutines enable simpler code by maintaining a single path of execution, as opposed to threads that are truly independent.

Not only does cocotb enable writing tests in what we would argue is a far stronger language than Verilog, it also connects us to the universe of Python modules which are now trivial to import into our tests.
We use Verilator for as much of our simulation needs as possible. Verilator is an open source tool which converts Verilog designs into a C++ class which can then be compiled along with other code to provide an in-process simulation of a given design.
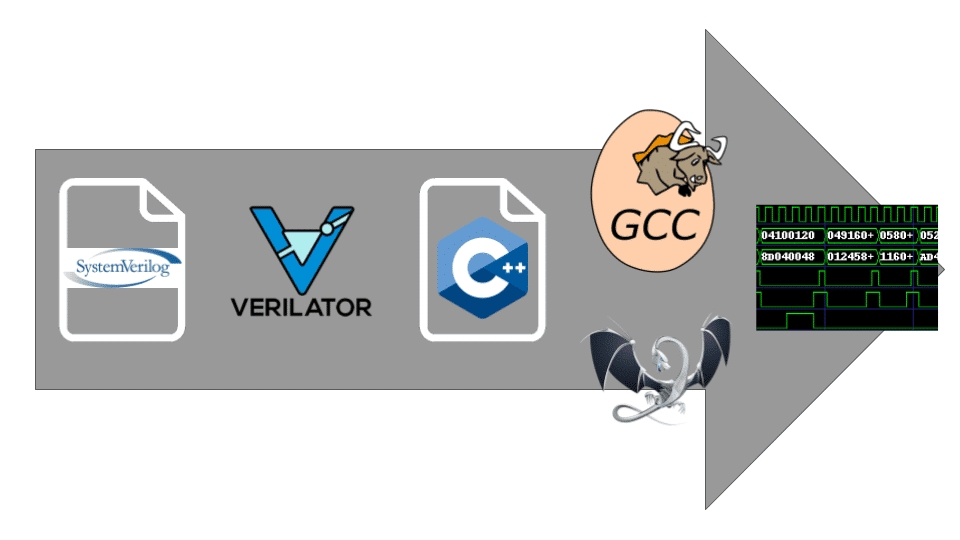
Verilator has some language features it does not currently support, such as delay controls and encrypted Verilog. For environments that require such code we use proprietary simulators instead. But this can be avoided for most of our testing. Verilator delivers very performant simulations when compared with proprietary simulators. And since verilated code does not have the licensing concerns that come with most proprietary EDA tools, we are able to leverage our compute resources such that every developer is able to have thousands of simulations running at any given point in time, instead of everyone wrestling over a handful of licenses.
We also work towards making sure that our tests that run against full chip simulations are portable to our lab environment. This requires some additional abstractions, but the upside is that one test can now run in simulation and against an actual FPGA. This has a few benefits. Of course, we’d like to hope that our simulations are faithful representations of the actual FPGAs our Verilog will produce. Unfortunately that is not always the case, as problems with our timing constraints, scripting, or just plain tool bugs can cause divergences. Running the tests again in the lab is definitely a nice backstop to have against such problems. Additionally, since simulations are slower than the actual hardware, we’re able to run tests at time scales not practically available to us in simulation.
Finally, we like to use continuous integration wherever it makes sense. We use Jenkins and other platforms for this. We use it to find regressions, try new pseudo-random seeds, automate builds, run tests in the lab, and streamline deployments. While our rationale is similar to most users, running EDA tools in platforms that were primarily intended for software flows does present some challenges. However, we think these are well worth the trouble so that we can let the robots do the tedious work and focus on more interesting challenges ourselves.
Conclusion
Hardware verification environments are not one-size-fits-all. It is definitely worth considering the broader organizational context and the tradeoffs at hand before building from scratch or making improvements in this space. At HRT, our use of open source along with our own development provides a verification environment that allows us to create hardware designs at a high velocity.