In this post, Wintern Hao Wang describes his main project, which yielded order-of-magnitude speed improvements in Ethereum data ingestion on our DeFi research platform.
Introduction
Before starting my work as a DeFi Intern at HRT this January, my experience trading NFTs and using various DeFi protocols taught me that coding on Ethereum is slow. I never worried too much, as 10 reads per second would certainly satisfy my personal needs.
However, if we want to perform research based on on-chain data and activities, that’s not going to cut it. In this blog post, we propose a simple way to make the reading speed more easily scalable.
How do people read from Ethereum
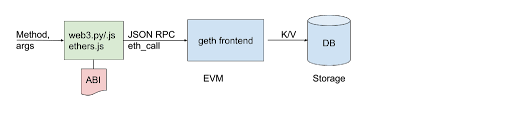
Currently, if a developer wants to read on-chain data, they would likely use a package such as web3.py or etheres.js to make HTTP requests to an endpoint. The endpoint could be a local hosted node or remote services provided by Infura or Alchemy. Infura and Alchemy will process the HTTP requests and return the data we want.
from web3 import Web3
w3 = Web3(Web3.HTTPProvider(ENDPOINT_URL))
w3.eth.get_block("latest")On the one hand, this means we don’t need to worry about the parsing of data stored in the database and web3.py would create the corresponding JSON RPC calls for us.
Then, what’s the problem?
Reading from Ethereum is Slow
contract = w3.eth.contract(USDC_ADDRESS, abi=ERC20_ABI)
for i in range(0,1000):
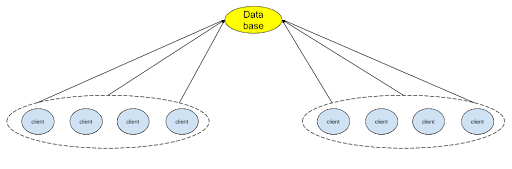
contract.functions.balanceOf(USER_ADDRESS).call()It would take roughly a minute to make 1000 queries. There are many different contracts and on-chain activities we need to pay attention to. At the beginning of my internship, I often heard other interns complaining that it would take an entire weekend to collect the data they wanted. A natural way of increasing read speed is to simply increase the number of clients making queries. If we were to have 500 clients splitting the query requests and performing the job independently, then would we successfully increase the speed of reads by 500 times? Unfortunately not. Simply adding more clients would not solve this problem completely, because the clients still need to make requests to the server which handles the HTTP requests from the clients and fetches the data from the database, so the server will get overloaded.
So why not increase our number of servers? If we have more servers and more clients, then each time a client makes a request, no single server becomes congested.
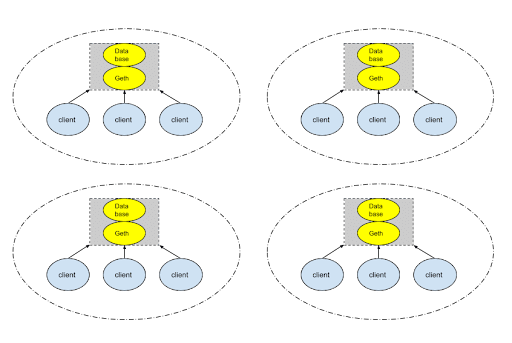
Read-Only Ethereum
If we could query Ethereum data in read-only mode, where every client simply reads from the same database, then we don’t need to run many nodes. If we freeze the state of the database, then we don’t even need one node.
If we need to increase the number of reads per second, we could simply add clients, which is more scalable and maintainable than spinning up more server nodes.
First Attempt
I started with Erigon, because it runs RPC daemon and the backend in separate processes, and it shares a decent amount of code with Geth. My first attempt was to move the RPC daemon into the client, so I could reduce the server’s work and get myself familiarized with the Erigon code base.
After digging into its code base and talking with my mentor, I realized that I needed to simulate the part of the code that sends the message to the remote server. When navigating the code and figuring out the connections among different functions in different files, debug.PrintStack() becomes really helpful, so I could know the top-level function that handles the API requests. Eventually I found handleMsg().
func (h *handler) handleMsg(msg *jsonrpcMessage) {
h.StartCallProc(func(cp *CallProc) {
stream := jsoniter.NewStream(jsoniter.ConfigDefault, nil, 4096)
answer := h.HandleCallMsg(cp, msg, stream)
})
}If we could initiate the RPC daemon on the client-side and directly make an HTTP request through the handleMsg function to the backend storing the database, then we have successfully moved the RPC daemon from the server end to the client end.
Python Integration
Web3.py will create the JSON message along with many other useful functionalities, so we would need to integrate our client-side RPC daemon with Web3.py.
Since both Erigon and Geth are implemented in Go, if we want to call a Go function in Python script, we would need to compile the Go code as a C shared library.
go build -buildmode c-shared -o <c-lib>.so <go-package>At the Python end, there is a package called CFFI (C Foreign Function Interface for Python). Through this package, we could load a C shared library and call the functions implemented in Go.
In order to integrate with Web3.py, we also need to make our customized provider. A provider defines the protocols and the RPC endpoint that the web3 client interacts with.
class HTTPProvider(JSONBaseProvider):
def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:
request_data = self.encode_rpc_request(method, params)
raw_response = make_post_request(
self.endpoint_uri,
request_data,
**self.get_request_kwargs()
)
response = self.decode_rpc_response(raw_response)
return responseHere is the code of HTTPProvider. When we try to get the latest block, the provider will help us create a JSON message like
{"jsonrpc":"2.0","method":"eth_getBlockByNumber","params":["latest", false],"id":1}It would also make a post request to the corresponding endpoint.
Therefore, we could override the make_request function and create our customized provider.
def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:
request_data = self.encode_rpc_request(method, params)
raw_response = self.call_go_package(request_data)
response = self.decode_rpc_response(raw_response)
return responseSwitching to Geth
After isolating the RPC daemon from the Erigon storage backend, I tried to make the backend read-only as well. It’s crucial to make Erigon read from a remote file system, such as NFS, otherwise we would still need to store a copy of the entire database on each client device.
However, I ran into an issue.
EROR[01-27|13:20:01.359] Erigon startup err="mdbx_env_open: block device required, label: chain dataI figured out the error code for this error message is ENOTBLK based on this GNU Manual. After searching the error code in Erigon’s codebase, I found that MBDX, the database that Erigon relies on, does not support remote file systems, and even considers the remote file system as an error.
MDBX_EREMOTE = ENOTBLKAs MDBX does not function well with remote file systems, I decided to look into Geth, which utilizes LevelDB, and should allow remote file system reads.
By making the database directory read-only, any writing attempts from Geth would result in permission errors, which I could use to find any code that attempts to modify the files.
There are several types of write attempts:
- Direct writes to the database (new blocks from P2P)
- Creating temporary files (key file, database journaling, and etc.)
- File locks
By disabling modules that attempt to write, I was able to modify Geth so that it could read from remote file systems, such as NFS. Even better, because I removed the use of file locking, I could now use multiple instances of Geth to read from the same directory.
Conclusion
Read-only Geth allows us to elastically scale read-only Ethereum workloads. Getting rid of the server side component enables parallelization without the maintenance burden of running live nodes.
Since other blockchains are direct forks of Go-Ethereum, this solution is portable to other blockchains, such as BSC.
We hope to merge this code into the go-ethereum codebase, so everyone can benefit from these new features. You can check out our pull request here.