Latency is often a crucial factor in algorithmic trading. At HRT, a lot of effort goes into minimizing the latency of our trading stack. Low latency optimizations can be arcane, but fortunately there are a lot of very good guides and documents to get started.
One important aspect that is not often discussed in depth is the role of huge pages and the translation lookaside buffer (TLB). In this series of posts, we’ll explain what they are, why they matter, and how they can be used. We’ll be focusing on the Linux operating system running on the 64-bit x86 hardware, but most points will apply to other architectures as well. We’ve tried to find a balance of providing the most accurate information without digging in the minutiae.
This series of posts is relatively technical, and requires some high-level understanding of operating systems (OS) concepts like memory management, as well as some hardware details such as the CPU caches. In the first post, we will explain the benefits of huge pages. In the second post, we will explain how they can be used in a production environment.
Memory Management 101
The hardware and operating system deal with memory in chunks. These chunks are called pages. For example, when memory is allocated or swapped by the operating system, it’s done in units of pages.
On the 64-bit x86 architecture, the default page size is 4 kilobytes (KiB). But x86 64-bit CPUs also support two other page sizes which Linux calls huge pages: 2MiB and 1GiB1. For simplicity’s sake, this series of posts is focused on 2MiB pages. 1GiB pages can also be helpful, but they’re so big that use cases for them tend to be more specialized.
11GiB pages are sometimes called gigantic pages as well
A quick primer on address translation
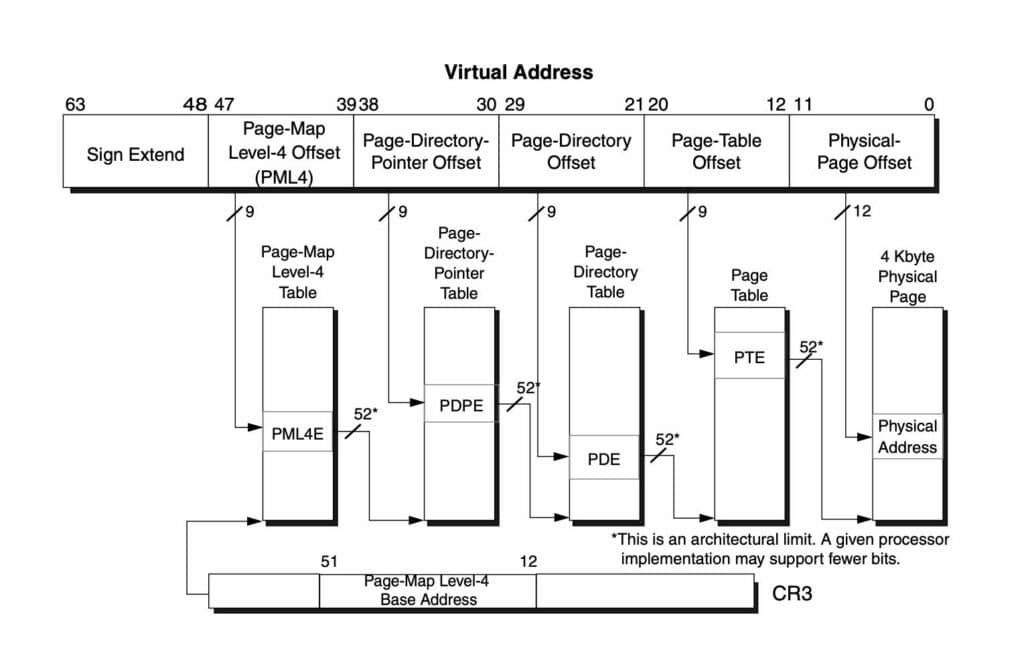
When regular programs run, they use virtual addresses to access memory. These addresses are usually just valid within the current process. The hardware and the operating system cooperate to map these into an actual physical address in physical memory (RAM). This translation is done per page (you can probably already see why the size of the page matters).
Because programs only see the virtual addresses, on every memory access the hardware must translate the virtual address visible to the program into a physical RAM address (if the virtual address is indeed backed by physical memory). Memory access means any loads or stores from/to the processor for data or instructions regardless of whether they’re cached.
These translations are stored by the operating system in a data structure called the page table which is also understood by the hardware. For each virtual page backed by real memory, an entry in the page tables contains the corresponding physical address. The page tables are usually unique for each process running on the machine.
Why accessing the page tables might significantly increase latency
Unless the program’s allocator and/or operating system are set up to use huge pages, memory will be backed by 4KiB pages. The page tables on x86 use multiple hierarchical levels. Therefore, looking up the physical address of a 4 KiB page in the page tables requires at least 3 dependent memory loads.2
2 4 loads if 5-level paging is supported by the CPU and enabled in the Linux kernel
The CPU cache will be used to try to fulfill these (similarly to any regular memory access). But let’s imagine that all of these loads are uncached and need to come from memory. Using 70ns as the memory latency, our memory access already has a 70*3=210 nanosecond latency — and we have not even tried to fetch the data yet!
Enter the translation lookaside buffer
CPU designers are well aware of this problem and have come up with a set of optimizations to reduce the latency of address translation. The specific optimization we are focusing on in this post is the translation lookaside buffer (TLB).
The TLB is a hardware cache for address translation information. It contains an up-to-date copy of a number of recently accessed entries in the page tables (ideally all entries in the page tables for the current process). Just like accessing the CPU caches is faster than accessing memory, looking up entries in the TLB is much faster than searching in the page tables3. When the CPU finds the translation it is looking for in the TLB, it’s called a TLB hit. If it does not, it’s a TLB miss.
But, just like the regular CPU caches, the TLB size is limited. For many memory-hungry processes, the entire page table’s information will not fit in the TLB.
3 Depending on the state of the cache, it will vary from 3x to ~80x times faster, though some of this latency could be hidden by speculative page walks.
How big is the TLB?
The TLB structure is not completely straightforward; we’ll approximate it to a set of entries in the hardware. A decent rule of thumb is that recent server x86 CPUs come with a TLB of about 1500-2000 entries per core (cpuid can, for example, be used to display this information for your CPU).
Therefore for processes that use 4KiB pages, the TLB can cache translations to cover 2000 (number of entries in the TLB) * 4KiB (the page size) bytes, i.e ~8MiB worth of memory. This is dramatically smaller than the working set of many programs. Even the CPU cache is usually considerably larger!
Now, let’s say we are using huge pages instead — suddenly our TLB can contain the translation information for 2000*2MiB = ~4GiB. That is much, much better.
Other benefits of huge pages
One huge page covers 512 times more memory than a 4KiB page. That means the number of entries in the page tables is also 512 times smaller for the same working set than if we were using regular pages. This not only greatly reduces the amount of memory used by page tables, but also makes the tables themselves easier to cache.
Additionally, the format of page tables for 2MiB is simpler than for regular pages, so a lookup requires one fewer memory access.
Therefore, even if a program gets a TLB miss for an address backed by a huge page, the page table lookup will be measurably (or even dramatically) faster than it would have been for a regular page.
A quick-and-dirty benchmark
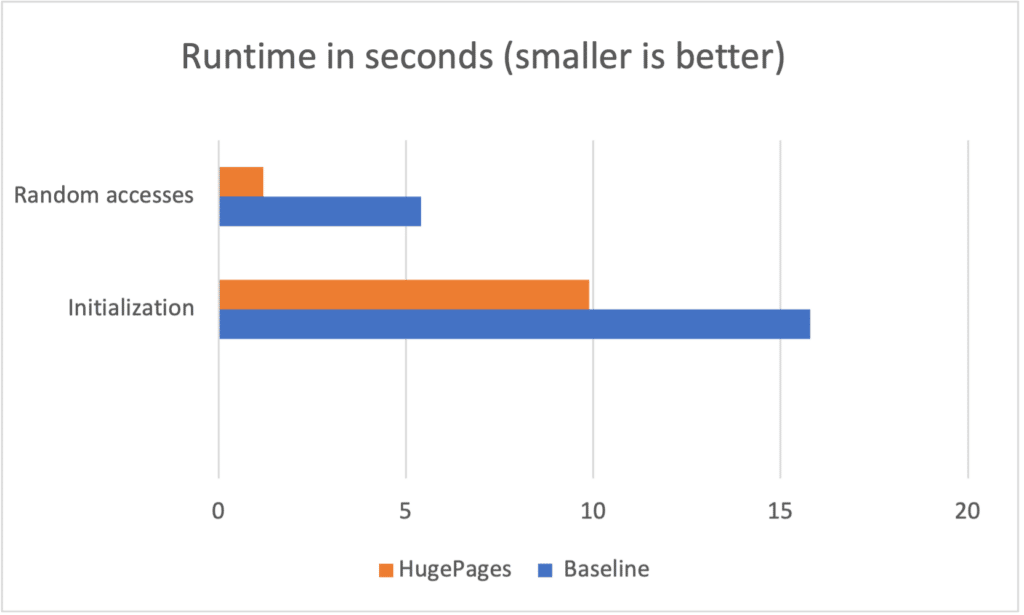
No post about optimization would be complete without a completely artificial benchmark 😀. We wrote a simple program that allocates a 32GiB array of double precision numbers. It then adds 130 million random doubles from this array (full source code is available here). On the first run, the program generates a random list of indices in the array then stores them in a file. Subsequent runs will read the file so memory accesses will be the same during each run.
We ran this program on an otherwise idle Intel Alder Lake machine. The baseline time for the initialization part of the program was 40% faster when using huge pages. The array is initialized linearly, which is the best case scenario for the hardware so the speedup is not dramatic. However, when doing random accesses to add the doubles, the runtime is decreased by a factor of 4.5. Note that the number of seconds for a run can vary significantly with small changes in the program or the use of different compilers. However, the performance improvement for huge pages remains quite clear.
When you should not use huge pages
Huge pages should be thought of as an optimization. Just like any other optimization, they may or may not apply to your workload. Benchmarking is important to determine whether it’s worth investing time in setting them up. In the second post of this series, we’ll detail how they can be used and list some substantial caveats.
Conclusion
On every memory access for code or data, the hardware translates virtual addresses into physical addresses. Using huge pages measurably speeds up this translation.
Huge pages also allow the TLB to cover a lot of memory. Ideally, we’d want our entire working set to be translatable by the TLB without ever going to the page tables. This reduces latency of memory access, and also frees some room in the CPU caches (which no longer need to contain as many cached page table entries).
If you find this content interesting and would like to know more about HRT, check out our website or consider applying to join our team!
Now that we’ve covered the advantages of huge pages, head over to part 2 to read more about the practicality (and challenges!) of using huge pages in a production environment.