Introduction
HAIL (HRT AI Labs) once again hosted many Algo Developer interns during the HRT 2023 Algo Summer Internship program. Like last year, these interns tackled a broad variety of problems that the HAIL team works on every day to apply artificial intelligence in trading. As one would expect from such an exceptional group, these interns made serious contributions to our research projects in the short five weeks they spent on a rotation with our team. This post will delve into three of those projects:
This post in our intern spotlight series highlights the work of three of our Software Engineering interns:
- Signal Architecture Search with Diverse Multi-Solution Genetic Algorithms by Jesse Chan
- Speed Up Hyperparameter Search with Graybox Bayesian Optimization by Ziqian Zhong
- Accelerating Quantitative Finance with GPU Computation by Emma Yang
Signal Architecture Search with Diverse Multi-Solution Genetic Algorithms
By Jesse Chan
A key part of algorithmic trading is the ability to anticipate price movements. Finding predictive “signals” is a difficult task; traditionally, signals were hand-crafted by researchers by blending market intuition with empirical analysis of market data. Although market intuition is helpful for signal creation, the space of possible signals is very large. It is reasonable to ask if we could utilize AI to craft signals that outperform or are complementary to the signals that humans create.
In this project, we used tick-level order book data directly from the stock exchange. The order book is a snapshot of the market, made up of various “bid” (buy) and “ask” (sell) offers at various prices and sizes. Tick data is fine-grained financial market data, where each datapoint corresponds to a change in the order book. The goal for our project was to find signals to predict short-term changes in price given only this data.
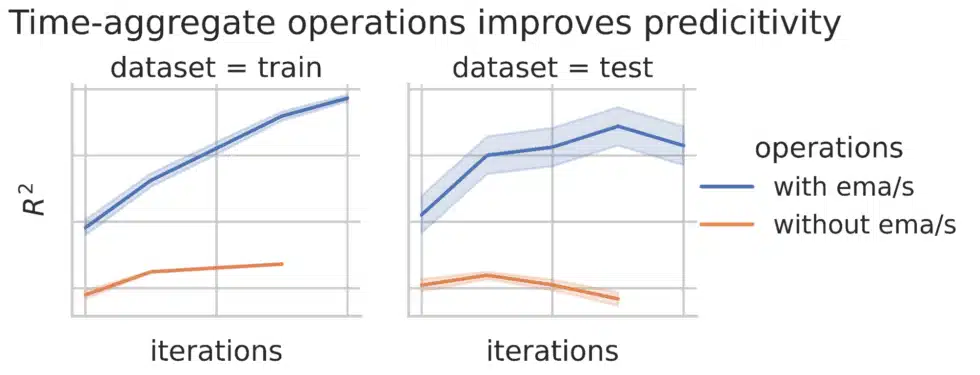
Designing an automated procedure to generate these signals is a two-step process. First, we must decide on the search space of possible signals and how we represent them. Second, we need a search algorithm that can effectively explore this space. We chose to represent the signal as a directed acyclic graph, where each node represents a function on its input. We must then decide which functions to allow. We found that fundamental operations like addition and subtraction are not sufficient. Since we are working with time-series data, defining operations that aggregate along the time axis allows us to capture trends in the data. We found that including exponential moving average (EMA) and exponential moving sum (EMS) as node operations substantially improves the quality of the signal.
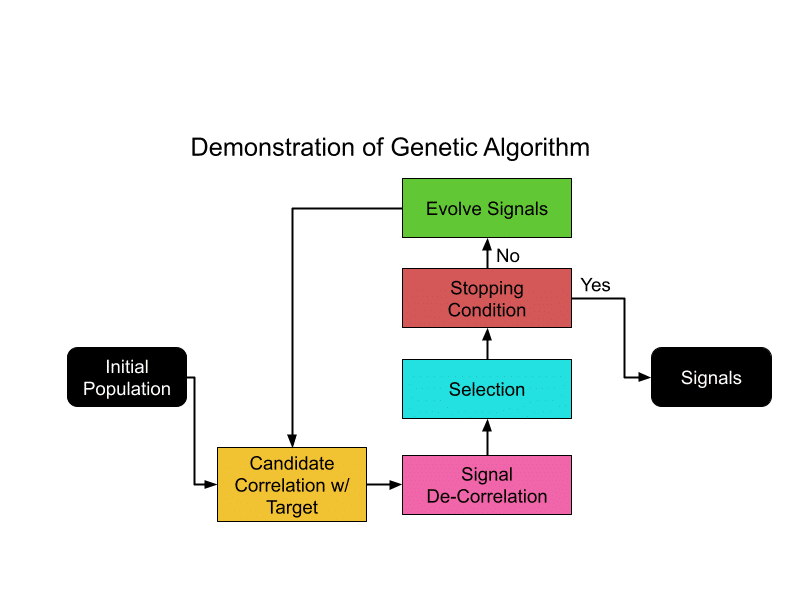
We found that genetic algorithms are well-suited for this task given the large amount of parallel computation possible with HRT’s compute resources. Genetic algorithms select the best candidates at each generation and “evolve” them to create a new generation, improving the overall quality of the candidate pool over time. However, a challenge with such an approach is that there can be a tendency to excel at finding a single optimal solution, rather than multiple distinct ones. In this particular problem, we believe that the best possible “signal” would be a combination of multiple signals, so we would prefer that the algorithm doesn’t converge on a best single signal. To address this, we attempted to decorrelate the signals selected at each generation. We expressed this via a “fitness function” that prefers signals that maximize the signal’s correlation with the target returns while minimizing correlation with other signals.
We found that the application of de-correlation pressure does lead to the generation of more diverse signals. When we combine the top signals in the population to predict the target, we obtain a better model than just using the top signals without the pressure. Overall, we find that this approach can generate predictive and diverse signals.
Speed Up Hyperparameter Search with Graybox Bayesian Optimization
By Ziqian Zhong
At HRT, Algo Developers develop new and exciting trading strategies which often have parameters like thresholds that need to be chosen empirically. One way to choose these parameters is by directly optimizing the performance of a strategy on a backtest. As backtests are costly in both time and computation resources, we strive for the best possible results using the fewest evaluations possible.
Suppose we have a scoring function that measures the performance of a trading strategy on a backtest. Our goal is then to find the set of parameters that maximize this score. It’s natural to approach this function as an expensive “blackbox” whose values we can query at any point. Bayesian optimization provides us an efficient way of doing so. The method maintains a belief (“posterior”) on the function: the expected values at each point and corresponding uncertainties, based on which the new points could be picked. For example, we may pick the point that is believed most likely to improve the current maximum (“Probability of Improvement”). After we observe the value at the newly picked point, we then update our belief and continue the process.
Blackbox Bayesian optimization is generally more efficient than simpler approaches like grid search and uniform sampling. In some cases, we can go even further if extra “structural” information is available for our scoring function. For example, the final scoring function might be a sum of functions on the same parameters, each of which may be evaluated separately. A relevant example would be if the total profit of a trading strategy could be expressed as the sum of profits over individual days. Using this structure is playfully called “graybox” optimization, as we’ve opened one layer of the blackbox but do not have full information about the function.
Applying the graybox approach to a sum of functions, we model our beliefs about each function that contributes to the sum, not just the value of the sum itself. This more elaborate model can integrate information from partial evaluations. For example, you can reduce uncertainty in the model by exploiting the correlation of one day’s profit with another’s for a similar choice of trading parameters. We ultimately obtain a graybox posterior distribution which we use to decide the next points to sample.
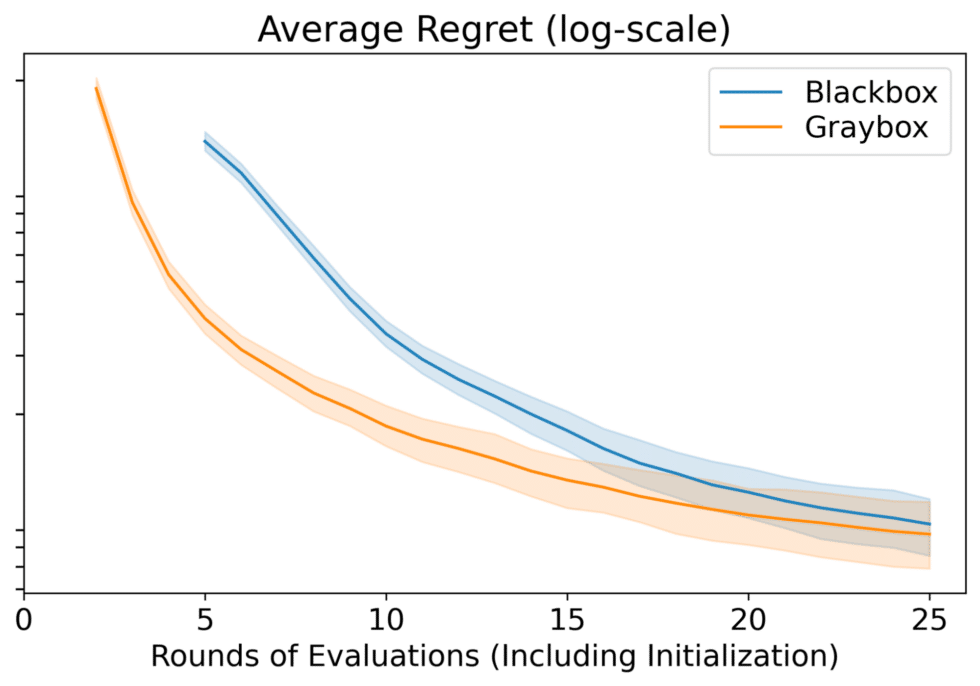
We evaluated blackbox and graybox Bayesian optimization by comparing their regrets — the difference between the maximum possible score computed with a much larger budget and the discovered maxima (how much value is lost compared to real maxima). Compared to blackbox Bayesian optimization, graybox Bayesian optimization gets us to better solutions earlier and generally produces better results over a range of computation budgets.
Accelerating Quantitative Finance with GPU Computation
By Emma Yang
HRT has a large amount of compute resources to use for training models, but Algo Developers can always benefit from faster training, whether it’s by training bigger models or trying more model variations in a given amount of time. These models ultimately drive HRT’s trading, so performance engineering is a way to directly affect the profitability of strategies.
Some of the models that HRT trains involve “tall & skinny” matrix multiplications. For example, if we have a time series with far more timesteps than features, then performing analyses like linear regression or applying transformations across the time series involves multiplying wide and tall matrices, or tall and small square matrices. If we can optimize this key operation, we should be able to improve overall training speed.
We began with investigating whether CUDA’s general matrix multiplication heuristic, provided through cuBLAS (CUDA Basic Linear Algebra Subroutine), picks the optimal algorithm for tall & skinny matrix workloads. cuBLAS uses a heuristic to determine a configuration of algorithm attributes such as the tile size, amount of shared memory, and split-K reduction factor of the matrix multiplication based on the data sizes of the operands. In addition to performing matrix operations, the cuBLAS API allows us to query the heuristic for the top algorithms by runtime for a given workload.
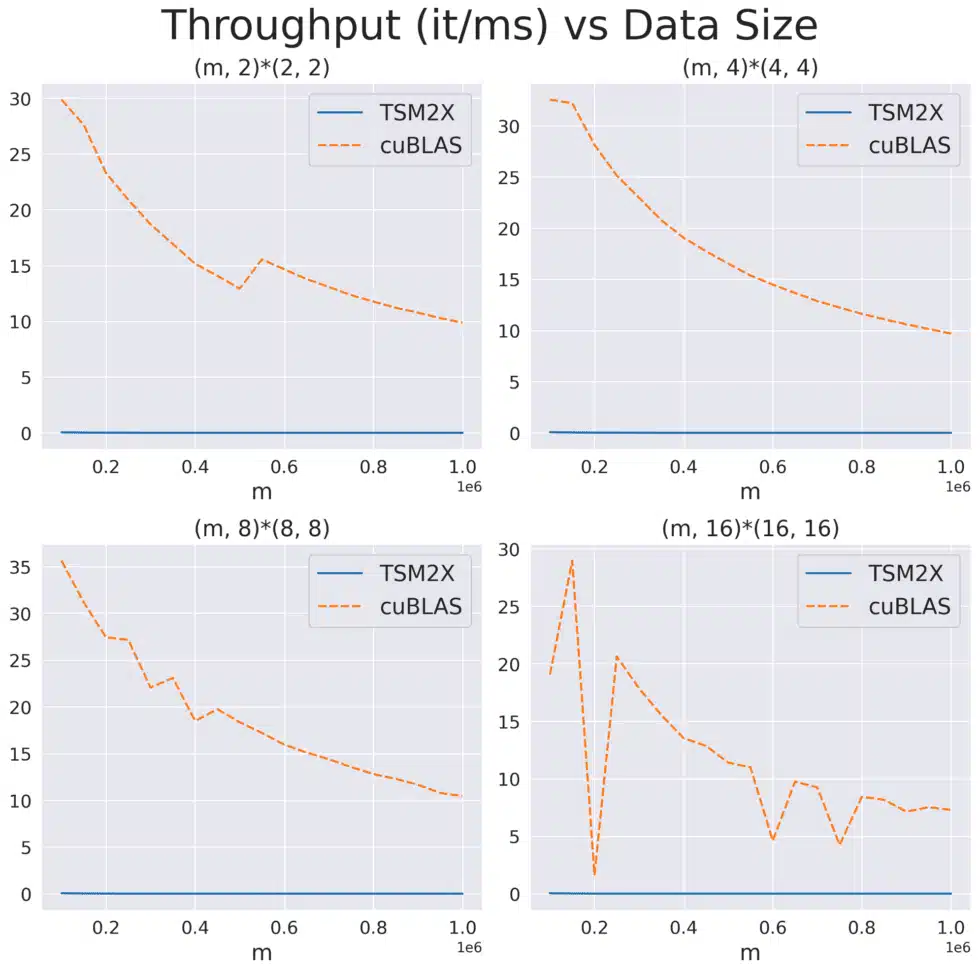
My goal was determine whether cuBLAS ever makes sub-optimal choices, given the unique nature of tall & skinny workloads. If algorithm choices were suboptimal, then we would expect anomalies in the linear trend of data size and runtime that could be observed through benchmarking each algorithm over a variety of matrix sizes. In particular, we were interested in matrices where the “tall” dimension was between 100,000 to 10 million and the “skinny” dimension was between 5 and 500.
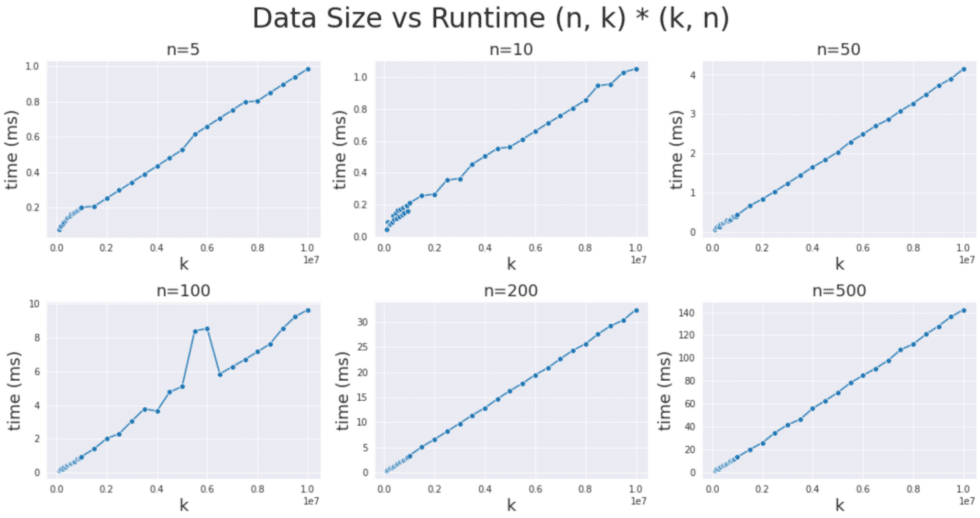
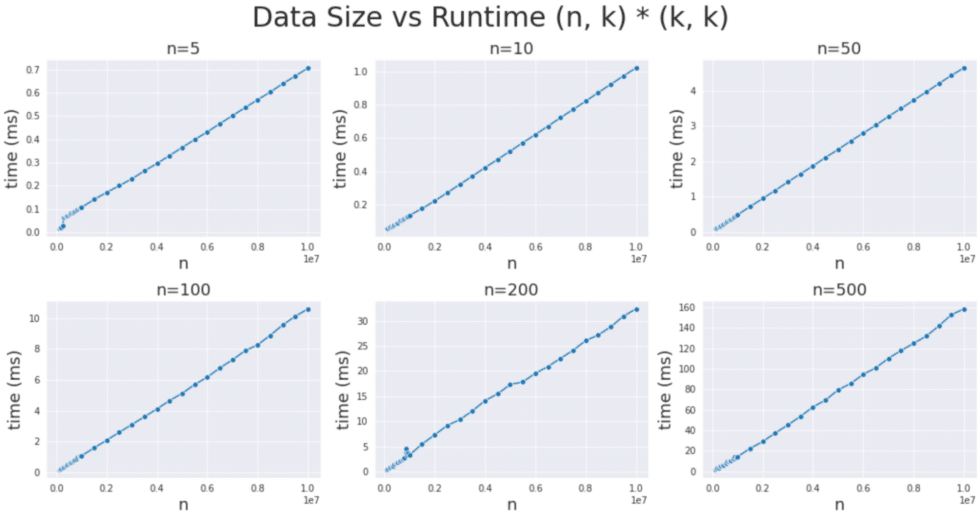
After benchmarking the top 10 algorithms chosen by the cuBLAS heuristic for each data size, we did not find any significant deviations from the expected linear relationship, indicating that cuBLAS is indeed making mostly optimal algorithm choices.
Seeing that cuBLAS’ heuristic was performing well in choosing amongst the algorithms in its search space, we looked to literature to find solutions that might be able to beat cuBLAS.
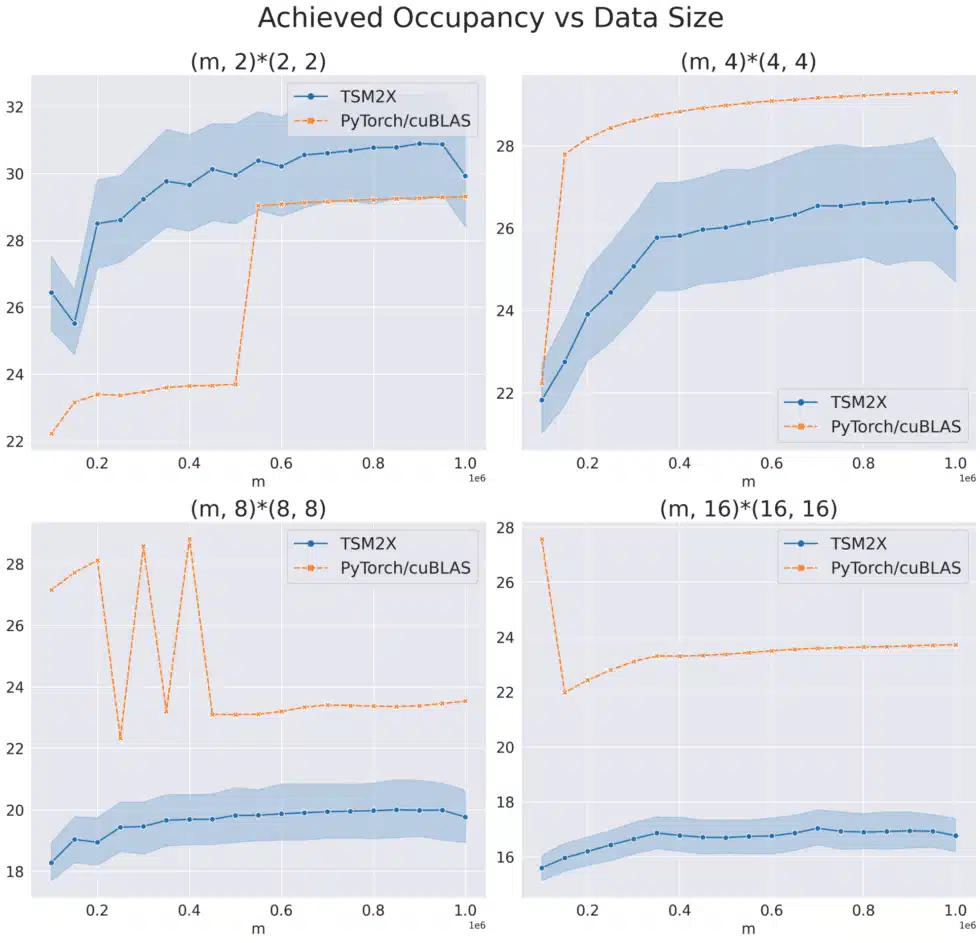
The paper “TSM2: optimizing tall-and-skinny matrix-matrix multiplication on GPUs” claims that their custom CUDA kernels for tall & skinny matrix multiplication outperforms cuBLAS in GPU occupancy and runtime on Kepler, Maxwell, Pascal, and Volta GPU architectures. However, when we implemented their proposed algorithm, TSM2X, and benchmarked TSM2X against cuBLAS for a variety of “tall times small” multiplications, we were not able to replicate the speedups from the paper; we found that TSM2X significantly under-utilizes the GPU and has significantly higher runtimes on Hopper (H100) GPUs.
This result shows that performance engineering is an ongoing challenge. As technologically sophisticated firms like HRT invest in this latest generation of hardware, we must constantly check that our models and systems are making the most of every bit of computing power they provide.