The ability to store and analyze vast amounts of data is table stakes for an algorithmic trading firm like HRT. Some of our storage requirements weren’t well met by existing solutions, so we decided to build and operate our own distributed filesystem, called Blobby.
Why?
HRT ingests a large amount of data. Algo researchers then use the data to develop and test their ideas, and these ideas can turn into trading strategies. Large-scale data is core to our business.
Much of HRT’s infrastructure resides on-premises. We have historically relied on a mix of storage solutions, such as Lustre, NFS filers, and various open-source engineered in house options. These have supported our workloads in the past, but as HRT’s storage needs have grown, we’ve hit significant limitations:
- Cost. Purchasing storage appliances from third-party vendors is expensive when storing hundreds of petabytes of data.
- Scale. At the scale we are building, HRT would be one of the largest users of open-source storage systems such as Ceph or Lustre.
- Scalability. Scaling our existing storage solutions has often been cumbersome, and in some cases, outright impossible. We wanted a system that can scale with minimal operational or user burden simply by adding commodity hardware.
- Multi-tenancy. HRT is home to many different teams and researchers with different workflows. These users need to be able to run experiments and train models without being disrupted by each other. Historically, we’ve dealt with noisy neighbors by limiting the concurrency of their jobs and in extreme cases allocating them their own isolated storage system. While partitioning resources is effective at isolation, it has led to stranded storage capacity and bandwidth, racking up considerable extra costs and operational overhead.
- Control. Owning the entire storage stack gives us full control to prioritize the properties that matter most to HRT. We can design the system to specifically meet the needs of our workloads, as well as fix issues in a timely manner instead of going through lengthy third-party debugging/fixing loops.
To overcome these limitations, we decided to build Blobby, our distributed filesystem. We are not the only ones to have taken this path: DeepSeek has 3FS, Meta has Tectonic, Google has Colossus.
Design Principles and Requirements
Building and operating a storage system is a significant undertaking. Large tech companies employ many engineers to build and operate such a system. HRT is a tiny firm compared to the likes of Google, Meta, or Amazon. Designing and developing Blobby with a very small team has required us to lean heavily on prior art and focus on the minimal set of requirements for HRT workloads:
- High aggregate throughput. Blobby is not designed for maximum single-client performance, but for sustained, high aggregate throughput across many concurrent clients.
- Durability. At scale, hardware failure is common, but data loss is unacceptable. Disks fail, network links flap, software upgrades go wrong – user data has to be safeguarded against these inevitable failures. We run continual “chaos testing” to ensure that Blobby safeguards data under complex failure scenarios.
- Simplicity and maintainability. As a small team, we have been deliberate about introducing complexity only when required. For example, because most HRT workloads write large files in a single pass, Blobby is append-only. If future clients need in-place updates, we would build that on top of Blobby as another layer.
Architecture
Much of our system is based on prior art like Meta’s Tectonic filesystem. A high-level picture:
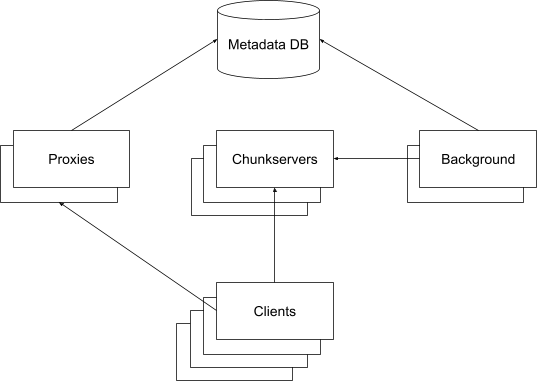
Boxes represent individual processes running on different “machines”, typically all within the same data center. Some of these processes run on bare-metal machines, some on virtual machines, and some in Kubernetes containers.
Arrows represent the direction in which communication is initiated, typically over TCP.
Data Layout
Blobby files are divided into blocks of arbitrary size, and blocks are broken down into chunks. Blobby supports two schemes for splitting blocks into chunks:
- Traditional replication, where the block’s data is written N times.
- Erasure coding, where the block is broken up into N data chunks. Erasure coding is applied to generate K parity chunks. Any N chunks can be used to generate all other chunks. For a more detailed explanation, see Backblaze Open-sources Reed-Solomon Erasure Coding Source Code.
Blobby’s default block layout is erasure coding with 6 data chunks and 3 code chunks; this allows a loss of any 3 chunks in a block without data loss. We also use a default chunk size of 8MB; each chunk read is a random read on a hard drive, and larger reads increase overall throughput.
Clients
The Blobby client is a C++ library that provides the following API:
// Metadata
list(path) -> [path]
rm(path)
rmdir(path)
mkdir(path)
// Reading
open(path) -> reader
pread(reader, off, len) -> bytes
close(reader)
// Writing
create(path) -> writer
append(writer, bytes)
flush(writer)
close(writer)This library is linked directly into end-user applications.
Blobby distributes the chunks of a file across the entire cluster. The Blobby client library communicates with Blobby servers on behalf of the end-user application to turn client reads/writes into RPCs to the correct servers into reads/writes of the relevant chunks. Data only flows between client and chunkservers for linear scalability.
Data Placement
When we create a block, we have to choose where to store that block’s chunks. One approach is to randomly choose chunkservers. This results in uniform data distribution, but may suffer from an increased probability of data loss at scale. We instead rely on ideas from Copysets: Reducing the Frequency of Data Loss in Cloud Storage. Instead of choosing randomly for each chunk, we choose from a smaller set of groups, reducing the likelihood of data loss if many disks/servers fail at the same time. We also ensure that each block’s chunks are in different racks to guard against data loss on rack failure.
Chunk Servers
Chunk servers store the actual chunk contents. Each chunk server has hundreds of terabytes of local storage attached. The API is intentionally simple: A chunkserver supports storing an entire chunk and reading a byte range from an existing chunk. Each chunk is represented as a file stored on XFS. While XFS has served us well as an initial implementation, there’s still room for improvement. As noted in Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution, it may not be the best long-term choice for a distributed storage system.
Metadata DB
The metadata database stores:
- Filesystem metadata. Directory tree structure, the blocks which make up a file, the chunkservers on which chunks have been placed on, etc.
- Cluster metadata. Disk and chunk server health as well as service-specific configuration files.
We use FoundationDB for our metadata database. It has several powerful properties and features that make it useful:
- Horizontal scalability: The metadata database runs on commodity machines and can serve more read/write traffic by adding machines.
- Fault tolerance: Replication of the metadata database means Blobby remains available even if the metadata database suffers an individual server failure.
- ACID transactions: This makes implementing operations which need to operate atomically over several rows (e.g. file deletion) trivial. As a result, we avoid needing a “garbage collector” for metadata inconsistencies like the one Tectonic describes.
- Strict serializability/consistency: Like ACID transactions, this significantly decreases implementation complexity.
DeepSeek also, independently, decided to use FoundationDB for 3FS metadata.
Proxy Servers
The proxy servers serve all non-data client operations. This includes:
- Metadata operations. For example, clients contact a proxy to learn which chunk server has the data for a particular range of file bytes. A proxy services these requests by reading/writing the filesystem metadata in the metadata database.
- Write steering. Clients contact a proxy to learn which disks to write chunks to. Proxies have a reasonably fresh view of cluster health, which allows them to steer writes towards writable disks.
Clients never talk directly to the metadata database. All reads/writes to the metadata database flow through a proxy server. This allows us to avoid buggy clients corrupting metadata, implement access controls, rate-limits or swap the metadata database under the hood when/if we need to.
Background Services
Our background services fulfill a variety of roles, from monitoring to failure detection and recovery. Clients do not directly interact with them, but they are vital to maintain the reliability of the system.
Shepherd
The shepherd maintains system health by:
- Detecting unhealthy servers and disks via regular health checks. Chunk servers constantly issue small reads and writes to their disks to determine disk health. The shepherd continuously sends status RPC requests to chunk servers, and considers a chunk server unhealthy if it does not reply for long enough.
- Updating cluster metadata to reflect the shepherd’s view of chunk server health. This allows:
- Proxies to steer new writes away from unhealthy servers/disks.
- The repair service to move existing data from unhealthy servers/disks to healthy ones.
We currently run a single shepherd instance per cluster. While this technically introduces a single point of failure, temporary unavailability of the shepherd does not impact client operations, as it is not in the critical path for reads or writes. That said, if our operational needs evolve, we are not bound to this design choice.
Repair
The repair service is responsible for recovering chunks in response to hardware failure. It continuously scans metadata for partially lost blocks and prioritizes recovering blocks that can tolerate the fewest additional chunk losses. To allow for horizontal scalability, each instance of the repair service operates on a separate shard of the block space.
Prober
Our training runs involve many jobs, each running on different hosts. Each job synchronously loads data through parallel data loading processes on each host, trains on that data, and then shares results with other jobs. A stall on any one data loading process will stall all jobs in the run, so it is very important to minimize tail latency.
We initially relied on metrics generated by real clients to monitor this. We run a variety of workloads across noisy hosts, so client-side slowness cannot always be directly attributed to Blobby. In order to get trustworthy client-perceived latencies, we run probers, dedicated clients that continuously read and write to Blobby in a controlled environment.
Conclusion
HRT currently has one Blobby cluster in “soft-production,” and is building out several additional clusters. Our NVMe-based cluster is the highest-throughput durable storage system at HRT. Our HDD-based clusters offer very high throughput at the lowest cost-per-GB. We are actively migrating workloads to Blobby clusters. Blobby offers enough storage and performance that researchers simply don’t have to pay close attention to things like quota, and can instead focus entirely on their research. The storage-dev team is excited to see what research “nearly unlimited bytes” will enable.
The storage-dev team is small but growing. If you are excited by foundational distributed systems, large-scale data pipelines, or low-latency compute infrastructure, we would love to hear from you. And if the name “Blobby” made you smile, you might be our kind of person. You can apply here or check out our careers page for all of our compute and storage roles.
Sources
- Availability in Globally Distributed Storage Systems
- Backblaze Open-sources Reed-Solomon Erasure Coding Source Code
- Copysets: Reducing the Frequency of Data Loss in Cloud Storage
- Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution
- Facebook’s Tectonic Filesystem:Efficiency from Exascale
- The probability of data loss in large clusters