Introduction
In keeping with our roots in high frequency trading, HRT moves fast. As is the case with any metric in engineering, speed has its tradeoffs. Over the last half-decade, HRT saw exponential growth in the size and interconnectedness of its research-oriented Python codebase, owing to a combination of a scrappy engineering culture that generally prizes “good enough” over “perfect,” our collaborative working environment that encourages code sharing between teams, and a period of accelerated growth. As our Python codebase grew to millions of lines, import times increased by an order of magnitude, code changes became more expensive to test, and lint times increased far outside the range of usefulness—we were experiencing the effects of code “tangle.”
Tangling
Code “tangling” is a concept HRTers borrowed from descriptions of the same issue in Dropbox publications1 about their own Python codebase. We call code “tangled” when its dependency graph has many overlapping cycles and unrelated portions of the codebase are coupled through indirect and unintuitive import paths. Tangling can be a problem in any large codebase (including in other languages)!
In our experience, tangling affects performance of both runtime imports and static analysis (e.g. mypy), and causes tight coupling which can reduce reliability2. Of these issues, our users find runtime import overhead to be the biggest problem, since it slows down the development iteration loop and wastes CPU time in the datacenter. This is likely more problematic for HRT than most other Python shops, as short-lived Python processes make up a considerable fraction of our computational workload.
The negative effects of tangling can increase quickly—a few misplaced imports and suddenly hundreds of modules are coupled together. The effects of import overhead are magnified by tangling because importing any module in a cycle ends up transitively importing all modules in that cycle (and their dependencies).
While some imports are very fast, there are many cases that incur significant overhead. One common way overhead sneaks in is through filesystem access—for example, the now deprecated pkg_resources module crawls the filesystem to locate resources. This process becomes particularly problematic when operating over our Network File System. A further source of computational overhead is the loading of bulky, monolithic C extensions by packages such as pandas and NumPy—and even proprietary extensions. Additionally, some of our pure-Python modules incur a range of costly static initialization steps like detecting environmental features or handling dynamic registration of classes or callbacks.
In isolation, each of these introduces manageable import overhead; however, in the most tangled portions of our codebase, the compounding effect can amount to over 30 seconds of import time for most programs. This overhead slows down the development iteration loop, and wastes CPU time in our distributed compute environment.
Dependency Management
At a high level, our approach to untangling is to establish and maintain a layered architecture where modules in lower layers don’t import from modules in higher layers. Establishing proper layering helps callers to only import what they need.
Ideally, our dependency graph should resemble a directed acyclic graph, where modules are topologically ordered by their assigned layers. However, in practice, some cycles are acceptable so long as they are relatively small and contained to one (sub)package.
Transitioning to a better dependency management paradigm requires identifying the current causes of tangling, refactoring the codebase to restructure dependencies, and putting in place dependency validation to avoid future regressions. And all of this work has to be done without pausing development in the codebase!
Tangle Tools: Understanding the Tangle
Once we understood that tangling underlay many of our developer experience problems, we set out to build a toolkit for analyzing the dependency graph of our codebase. Tangle Tools analyzes Python source code to generate a dependency graph of the entire codebase (nodes correspond to modules and edges to imports). Our users can then utilize the command line and browser interfaces to discover, navigate, and refactor dependencies.
A typical untangling workflow involves:
- Finding an unwanted transitive dependency
- Tracing import paths from a source to the unwanted dependency
- Computes a flow network between the source and dependency
- Identifies which edges would reduce flow if removed
- Refactoring imports to disconnect the source from the dependency
- Utilizes code transformations to automate common refactors (e.g. moving a symbol to a new module and updating existing references)
- Putting dependency validation in place to avoid regressions
- Users write dependency rules to constrain the dependencies of their modules
- These rules are checked in our continuous integration pipeline
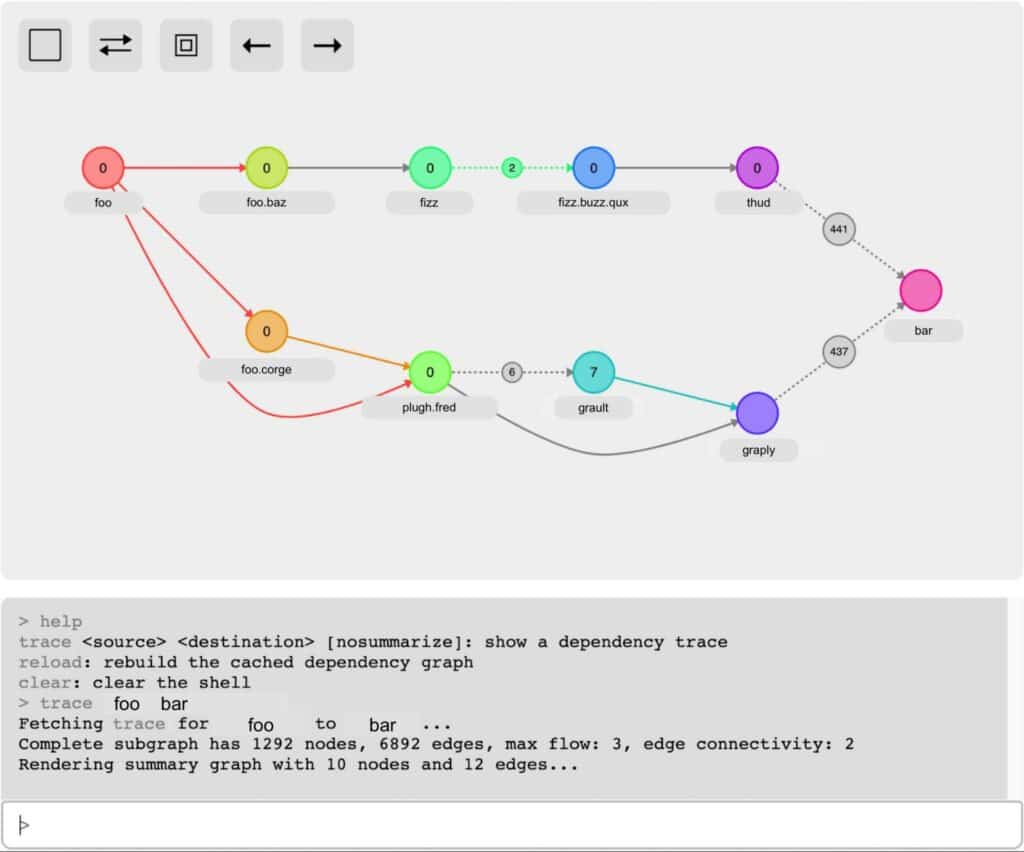
None of this would have been possible without extensive use of open source libraries! We used Python’s built-in ast library to parse our Python source code for imports. This parsing work was parallelized via the stdlib’s powerful concurrent.futures module, allowing us to quickly process thousands of modules. Under the hood we use networkx’s directed graph data structure and extensive library of graph algorithms–we found the flow algorithms to be especially useful. Finally, we use the libcst library to perform automated source code refactors, written as transformations to the concrete syntax tree.
Conclusion
By developing these dependency management and refactoring workflows we’ve been able to make significant progress on untangling. Previously, finding import dependencies was a slow manual process, and refactoring dependencies was a game of whack-a-mole. Now we can navigate our full dependency graph and find efficient refactors that address the root causes of tangling.
1 https://dropbox.tech/application/our-journey-to-type-checking-4-million-lines-of-python
2 https://en.wikipedia.org/wiki/Coupling_(computer_programming)