Diffusion models are a widely popular model class for non-autoregressive generative modeling, yielding spectacular results in problem settings such as image generation. More recently, their application has been extended beyond computer vision into generative problems in areas such as NLP. In this project, we will explore their applicability to generate sequences of stock returns. Beyond generating random walks that capture key characteristics exhibited by stock returns (e.g. fat tails), we study a variety of problem settings to showcase diffusion models’ ability to model stock returns, focusing particularly on joint and conditional modeling. A key challenge persists in defining meaningful evaluation metrics to benchmark our models’ capabilities. In this way, we aim to demonstrate that our models capture ever more intricate aspects of the underlying return distributions.
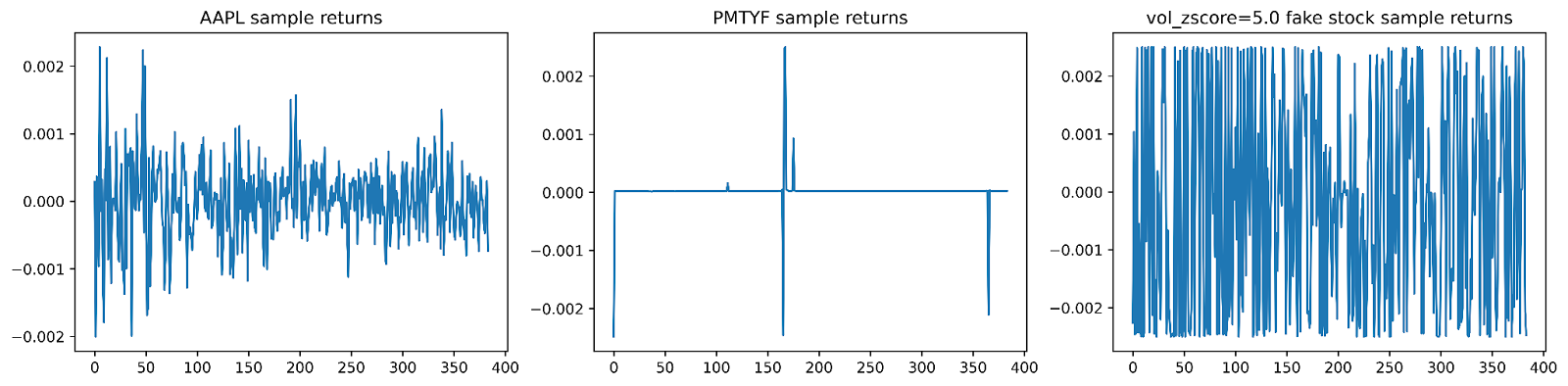
A natural question is whether we can generate sample returns conditioned on a given stock like AAPL or GOOG. We can train a model on returns with one-hot encodings for the stock, but a drawback of this approach is that we would need to retrain every time we want to generate samples for a new stock. Instead, in the same way that diffusion models condition on textual prompts by embedding them into a latent space, we can think of market metadata, like volume traded or historical volatility, as the latent features of a stock and train our model accordingly. This allows us to generate a wide variety of samples, even illiquid stocks with sparse returns or highly volatile stocks, without explicitly training on every stock. Plus, we can then finetune this large model for specific tasks.
Another problem we think about is modeling cross-sectional returns across different stocks. For instance, we would expect some correlation between AAPL returns and similar tech stocks like GOOG; can a diffusion model generate these jointly? In image generation, diffusion models learn the joint distribution of red, green, and blue channels, so a natural way to model cross-sectional returns is to train a model on samples whose channels are returns for each stock.
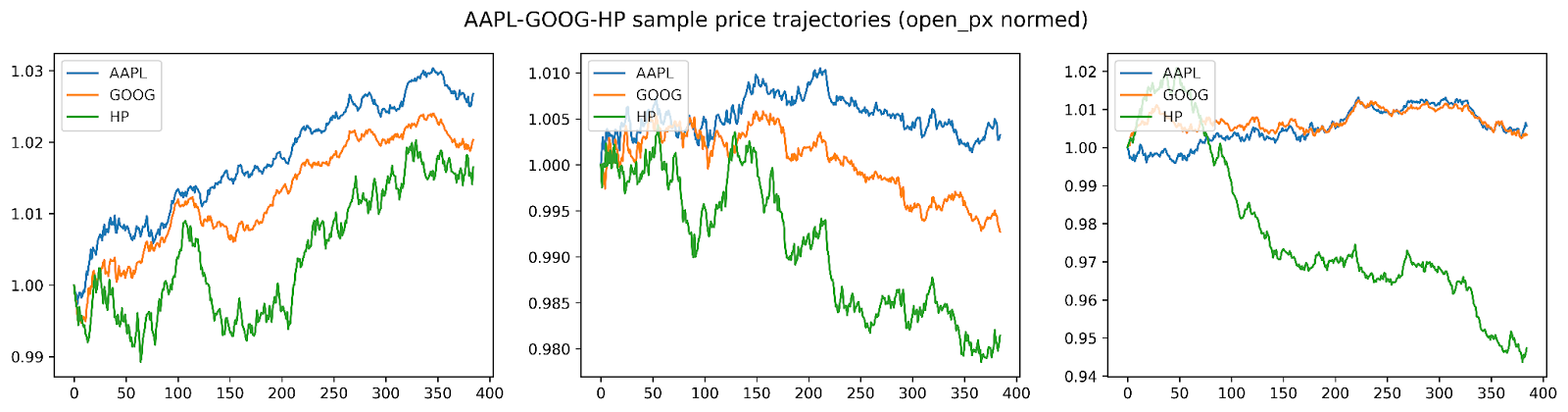
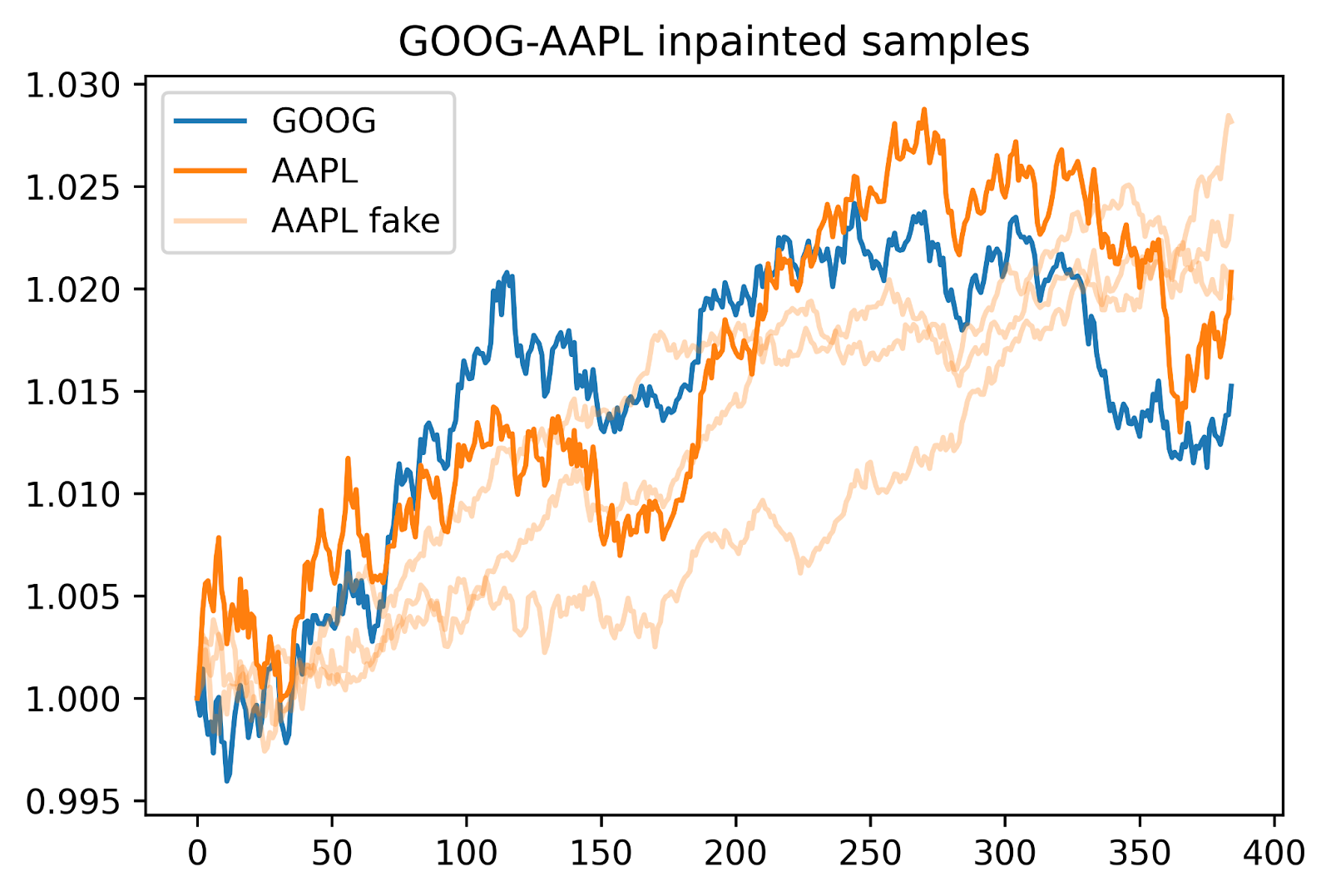
We can also try to generate returns conditioned on another return trajectory; if we are given sample GOOG returns, how do corresponding AAPL returns look? Given an image with missing regions, a diffusion model can inpaint these regions with new, semantically reasonable content by first adding noise, then sequentially denoising the image and resampling from the known regions. But what if we masked entire channels? In our use case, we mask the channel for one stock (e.g. AAPL) and use our cross-sectional model to inpaint these channels conditioned on the other stock (e.g. GOOG). This works even without retraining the model for inpainting tasks!
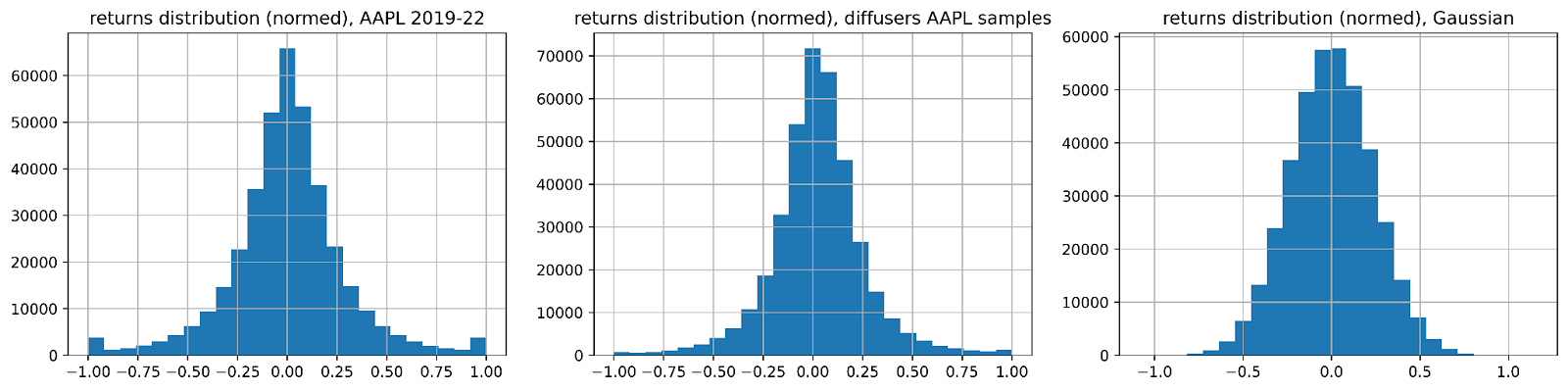
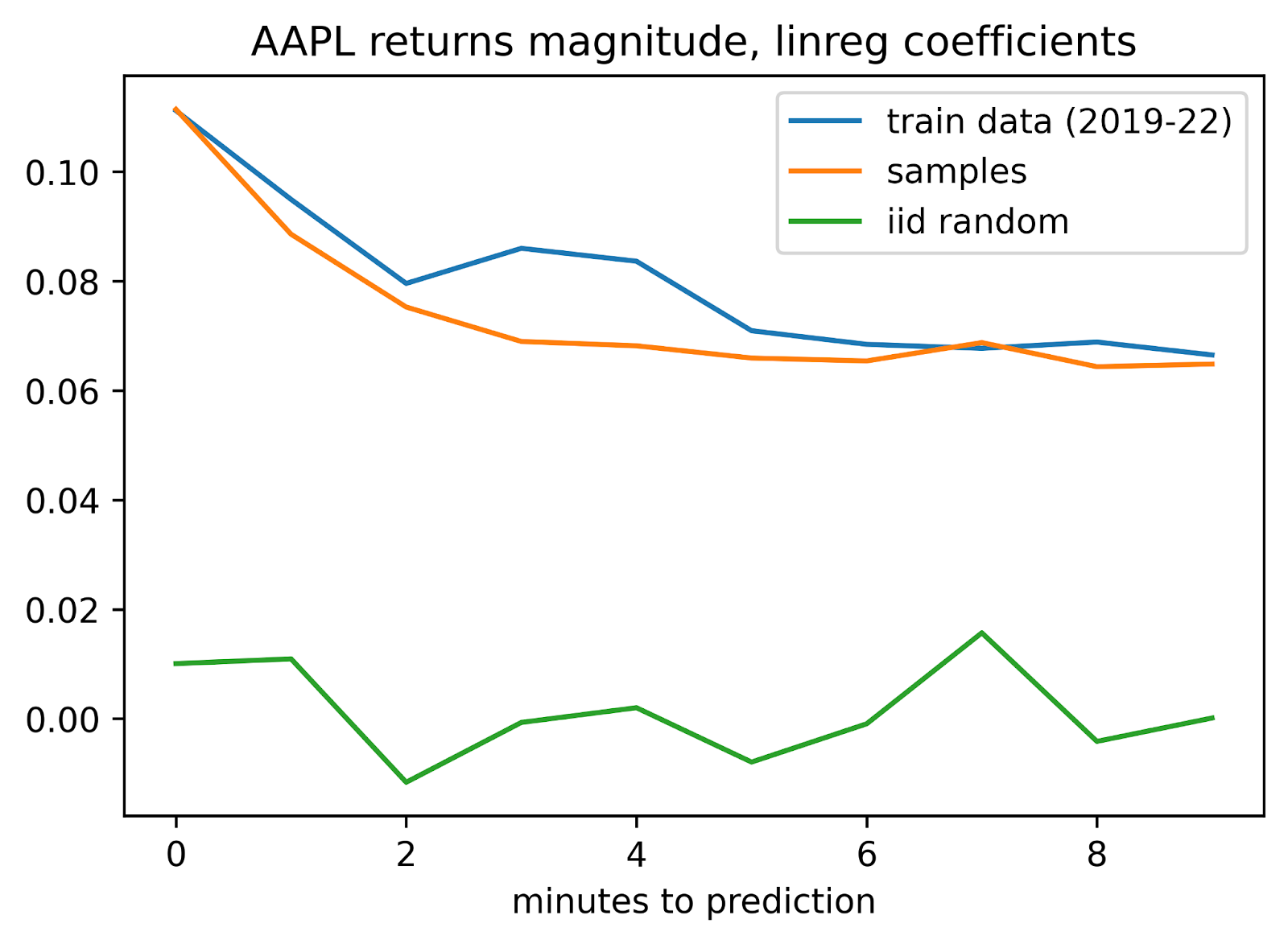
While it is nice that these models can generate a variety of novel samples, how can we evaluate whether these samples are reasonably in-distribution? We can sanity-check by asking the model to generate many samples, then measure their fidelity to distributions of some aggregate metrics. For instance, returns of liquid stocks tend to be more fat-tailed than normal distributions, and daily volatility tends to be right-skewed. We’d also expect that “market signals” present in the original data would also be present in our synthetic data. For instance, returns are autocorrelated—and when predicting the magnitude of returns, we see that returns from a minute ago hold more predictive power than, say, returns from ten minutes earlier.
Ultimately, we found that diffusion models could be potentially powerful tools in generating synthetic time-series data like stock returns. As non-autoregressive models, diffusion models do not seem to struggle with degenerative issues like mode collapse, which is an issue we have seen in autoregressive models like transformers (which we’ve tried before!) or GANs.